- NLP4LIFE: https://github.com/sarahESL/CLEFeHealth2020-multilabel-bert
- Exeter: https://github.com/aollagnier/eda_classification
- SWAP: https://github.com/marcopoli/CODIESP-10
- IAM: https://github.com/scossin/IAMsystem
- ICB-UMA: https://github.com/guilopgar/CLEF-2020-CodiEsp
- Hulat: https://github.com/pqueipo/Codiesp-CLEF-2020-eHealth-Task1
- IMS: https://github.com/gmdn/CLEF2020
- Baseline: https://github.com/tonifuc3m/codiesp-baseline-lookup
Description of the Corpus
Datasets can be already Download it from Zenodo.
This CodiEsp corpus or data used for this track consists of 1,000 clinical case studies selected manually by a practicing physician and a clinical documentalist, comprising 16,504 sentences and 396,988 words, with an average of 396.2 words per clinical case. It is noteworthy to say that this kind of narrative shows properties of both, the biomedical and medical literature as well as clinical records. Moreover, the clinical cases were not restricted to a single medical discipline, and thus cover a variety of medical topics, including oncology, urology, cardiology, pneumology or infectious diseases.
The CodiEsp corpus is distributed in plain text in UTF8 encoding, where each clinical case is stored as a single file whose name is the clinical case identifier. Annotations are released in a tab-separated file with the following fields:
articleID ICD10-code
Tab-separated files for the third sub-track on Explainable AI contain an extra field that provides the position in the text of the text-reference:
articleID label ICD10-code text-reference reference-position
Below we show an example of an annotated clinical case in the Brat visualization tool.

The CodiEsp corpus has 18,483 annotated codes, of which, 3427 are unique. These are divided into two groups:
- ICD10-CM codes (CIE10 Diagnóstico in Spanish). They are codes belonging to the International Classification of Diseases, Clinical Modification and are tagged as DIANOSTICO.
- ICD10-PCS codes (CIE10 Procedimiento in Spanish). They are codes belonging to the International Classification of Diseases, Procedure codes (related to procedures performed in hospitals) and their tag is PROCEDIMIENTO.
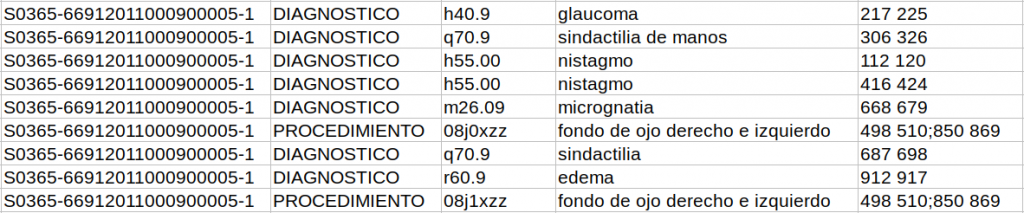
Moreover, codes are annotated with a reference in the text that justifies the coding decision. There are continuous and discontinuous references, having the latter several parts distributed along with the text.
In the case of the previous clinical case, the provided tab-separated file for the first sub-track (ICD10-CM coding) contains the following information:
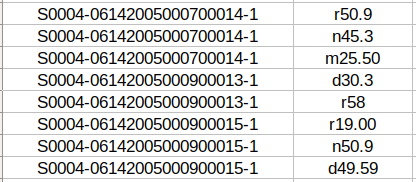
In the third sub-track, the tab-separated file has extra columnS of information that specify the reference itself and the label it has (DIAGNOSTICO or PROCEDIMIENTO) and the position in the text where the reference is taken from. In the case of discontinuous references, different sections of the reference are separated by a semicolon.
The entire CodiEsp corpus has been randomly sampled into three subsets, the training, development and test set. The training set comprises 500 clinical cases, and the development and test set 250 clinical cases each. Together with the test set release, we will release an additional collection of more than 2,000 documents (background set) to make sure that participating teams will not be able to do manual corrections and also promote that these systems would potentially be able to scale to larger data collections.
Datasets
Datasets can be already downloaded from Zenodo.
The CodiEsp corpus has been randomly sampled into three subsets: the train, the development, and the test set. The training set contains 500 clinical cases, and the development and test set 250 clinical cases each.
CodiEsp corpus will be published translated to English during the week previous to the test set release (10-14 February).
Train set
The train set is composed of 500 clinical cases. Download it from Zenodo.
Development set
The Development set is composed of 250 clinical cases. Download it from Zenodo.
Test and Background set
The test set has 250 clinical cases. The background set is composed of 2,751 clinical cases. Download them from Zenodo.
Test set with Gold Standard annotations
The Test set is with Gold Standard annotations is composed of 250 clinical cases. Download it from Zenodo.
Additional Datasets
Additional set 1 – Abstracts with ICD10 codes.
To expand the train and development corpora, a JSON file with abstracts from Lilacs and Ibecs with ICD10 codes (ICD10-CM and ICD10-PCS) associated with them (CIE10 in Spanish) is provided. Download it from ZENODO.
The format of the JSON file is the following:
{'articles':
[{'title': 'title',
'pmid': 'pmid',
'abstractText': 'abtract (in Spanish)',
'Mesh':
[{'Code': 'MeSHCode',
'Word': 'reference',
'CIE': [CIE10_1, CIE10_2, ...]},
...]
},
...]
}
There are 176 294 abstracts with an average of 2.5 ICD10 codes per abstract.
In addition, the same additional dataset is provided in the CodiEsp format: abstracts are distributed in individual UTF-8 text files and a tab-separated file summarizes the JSON information in four columns:
articleID label ICD10-code word
Additional Resources
Evaluation Script
- Official evaluation script: Available at GitHub.
This is the official evaluation script of the task. See Evaluation for more information about the evaluation and Evaluation library and Examples sections for even more clarity.
Additional Datasets
- Spanish abstracts with ICD10 codes. Download it from Zenodo.
It is a collection of abstracts in Spanish with ICD10 codes.
It can be used to improve system training.
For more information, see the Datasets page or Zenodo webpage. - Translated to Spanish corpus with ICD10 codes. Download it from Zenodo.
It is a collection of abstracts in Spanish (machine-translated from English) with ICD10 codes.
It can be used to improve system training. - English, Spanish and Portuguese clinical case reports (639 for each language) annotated with medical diagnostic codes from the ICD10-CM. Download from GitHub.
It is a collection of abstracts in 3 languages with ICD10 codes.
It can be used to improve system training.
Linguistic Resources
- CUTEXT. See it on GitHub.
Medical term extraction tool.
It can be used to extract relevant medical terms from clinical cases. - SPACCC POS Tagger. See it on Zenodo.
Part Of Speech Tagger for Spanish medical domain corpus.
It can be used as a component of your system. - NegEx-MES. See it on Zenodo.
A system for negation detection in Spanish clinical texts based on NegEx algorithm.
It can be used as a component of your system. - AbreMES-X. See it on Zenodo.
Software used to generate the Spanish Medical Abbreviation DataBase. - AbreMES-DB. See it on Zenodo.
Spanish Medical Abbreviation DataBase.
It can be used to fine-tune your system. - MeSpEn Glossaries. See it on Zenodo.
Repository of bilingual medical glossaries made by professional translators.
It can be used to fine-tune your system.
Terminological Resources
- Valid codes for the task. Download it here.
- Spanish Ministry of Health official CIE10 browser. See the documentation page for the 2018 version.
ICD10 terminology in Spanish is named CIE10. It is managed by the Ministry of Health. - Diseases and symptoms lexicon with MESH and ICD10 codes. List of disease and symptoms terms extracted from Spanish clinical texts. They are mapped to MESH and from MESH to ICD10.
It can be used as gazetteers or dictionaries.
Download it here. - More soon published.
Established Coding Systems
Other Relevant Systems
Annotation Guidelines
Datasets can be already Download it from Zenodo.
A complete list of relevant Diagnóstico and Procedimiento codes for the task is available at Zenodo.
Annotation guidelines may be found here.
The annotation process of the CodiEsp corpus was carried out in collaboration with terminology experts. Annotators followed an iterative process of training until a high inter-annotator agreement (IAA) was reached. The final, inter-annotator agreement measure obtained for this corpus was calculated on a set of 50 records that were double annotated (blinded) by two different expert annotators, reaching a pairwise agreement of 80.5% on the annotated codes.
Documents were coded with the 2018 version of CIE10 (the Spanish official version of ICD10-Clinical Modification and ICD10-Procedures) and inspired by the “Manual de Codificación CIE-10-ES Diagnósticos 2018” and the “Manual de Codificación CIE-10-ES Procedimientos 2018” provided by the Spanish Ministry of Health. There are two types of CIE10 codes: Diagnóstico and Procedimiento.
There were differences in the annotation of Diagnóstico and Procedimiento codes:
- Diagnóstico. ICD10-Diagnostico (equivalent to ICD10-CM) terminology is a tree-shaped terminology. Codes with a greater number of characters are more granular. Annotated codes are minimum 3-character long.
- Procedimiento. ICD10-Procedimiento (equivalent to ICD10-PCS) terminology is an axial terminology with 7 axes. Then, every Procedimiento code has 7 characters. In a real-world scenario, coders can use context information (other documentation, ask healthcare professionals involved in the case, etc) to obtain enough information to fill the 7 characters. This is not the case in clinical cases. Therefore, codes with only 4 characters (the first 4 axes) are allowed.
A complete list of relevant Diagnóstico and Procedimiento codes for the task is available at Zenodo.
The annotation of the entire set of entity mentions was carried out by terminology experts. Moreover, technical assistance in terms of the annotation interface was offered during the entire corpus development process.
Annotation guidelines may be found here.