Datasets can be already Download it from Zenodo.
This CodiEsp corpus or data used for this track consists of 1,000 clinical case studies selected manually by a practicing physician and a clinical documentalist, comprising 16,504 sentences and 396,988 words, with an average of 396.2 words per clinical case. It is noteworthy to say that this kind of narrative shows properties of both, the biomedical and medical literature as well as clinical records. Moreover, the clinical cases were not restricted to a single medical discipline, and thus cover a variety of medical topics, including oncology, urology, cardiology, pneumology or infectious diseases.
The CodiEsp corpus is distributed in plain text in UTF8 encoding, where each clinical case is stored as a single file whose name is the clinical case identifier. Annotations are released in a tab-separated file with the following fields:
articleID ICD10-code
Tab-separated files for the third sub-track on Explainable AI contain an extra field that provides the position in the text of the text-reference:
articleID label ICD10-code text-reference reference-position
Below we show an example of an annotated clinical case in the Brat visualization tool.

The CodiEsp corpus has 18,483 annotated codes, of which, 3427 are unique. These are divided into two groups:
- ICD10-CM codes (CIE10 Diagnóstico in Spanish). They are codes belonging to the International Classification of Diseases, Clinical Modification and are tagged as DIANOSTICO.
- ICD10-PCS codes (CIE10 Procedimiento in Spanish). They are codes belonging to the International Classification of Diseases, Procedure codes (related to procedures performed in hospitals) and their tag is PROCEDIMIENTO.
Moreover, codes are annotated with a reference in the text that justifies the coding decision. There are continuous and discontinuous references, having the latter several parts distributed along with the text.
In the case of the previous clinical case, the provided tab-separated file for the first sub-track (ICD10-CM coding) contains the following information:
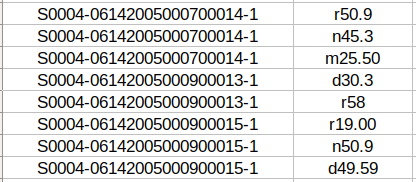
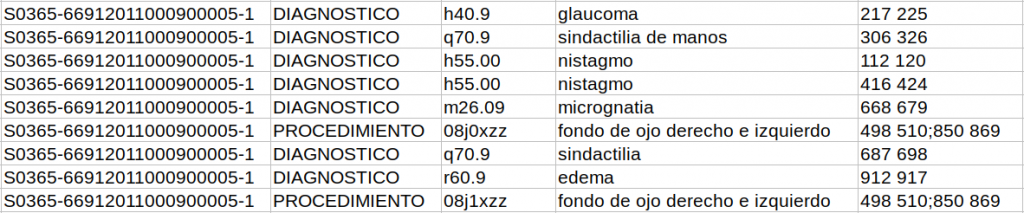
In the third sub-track, the tab-separated file has extra columnS of information that specify the reference itself and the label it has (DIAGNOSTICO or PROCEDIMIENTO) and the position in the text where the reference is taken from. In the case of discontinuous references, different sections of the reference are separated by a semicolon.
The entire CodiEsp corpus has been randomly sampled into three subsets, the training, development and test set. The training set comprises 500 clinical cases, and the development and test set 250 clinical cases each. Together with the test set release, we will release an additional collection of more than 2,000 documents (background set) to make sure that participating teams will not be able to do manual corrections and also promote that these systems would potentially be able to scale to larger data collections.