The CodiEsp evaluation script can be downloaded from GitHub.
Please, make sure you have the latest version.
Participants will submit their predictions for the test set and the background set. Both will be released together so that they cannot be separated to make sure that participating teams will not be able to do manual corrections and also that these systems are able to scale to larger data collections. However, predictions will only be evaluated for the test set.
CodiEsp-D and CodiEsp-P: MAP
For sub-tracks CodiEsp-D and CodiEsp-P, participants will submit their coding predictions ranked. For every document, a list of possible codes will be submitted ordered by confidence or relevance (codes not in the list of valid codes will be ignored). Then, since these sub-tracks are ranking competitions, they will be evaluated on a standard ranking metric: Mean Average Precision (MAP).
MAP is the most established metric in ranking problems. It stands for Mean Average Precision, where the Average Precision represents the average precision of a document at every position in the ranked codes. That is, precision is computed considering only the first ranked code; then, it is computed considering the first two codes, and so on. Finally, precision values are averaged over the number of codes in the gold standard (the relevant number of codes):
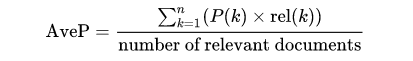
MAP is the most standard ranking metric among TREC community and it has shown good discrimination and stability [1]. Individual average precisions are equivalent, in the limit, to the area under the precision-recall curve; therefore, MAP represents the mean of the areas under the precision-recall curve.
It favors systems that return relevant documents fast [2] since those systems would have a higher average precision for every clinical case of the test set. Finally, contrary to other ranked evaluation metrics, it is easy to understand if precision and recall concepts are already understood; it takes into account all relevant retrieved documents; and information is stored in a single point, which eases comparison among systems.
CodiEsp-X: F-score
For the Explainable AI sub-track, the explainability of the systems will be considered, in addition to their performance on the test set.
To evaluate both explainability and performance of a system, systems have to provide a reference in the text that supports the code assignment (codes not in the list of valid codes will be ignored). That reference is cross-checked with the true reference used by expert annotators. Only correct codes with correct references are valid. Then, Precision, Recall, and F1-score are used to evaluate system performance (F-score is the primary metric).
Precision (P) = true positives/(true positives + false positives)
Recall (R) = true positives/(true positives + false negatives)
F-score (F1) = 2*((P*R)/(P+R))
Special cases:
- In case one single code has several references in the Gold Standard file, acknowledging only one is enough.
- For discontinuous references, the metric considers that the reference starts at the start position of the first fragment of the reference. Equivalently, the reference is considered to end at the final position of the last fragment of the reference.
References
[1] Christopher D. Manning, Prabhakar Raghavan and Hinrich Schütze, Introduction to Information Retrieval, Cambridge University Press. 2008.
[2] L. Dybkjær et al. (eds.), Evaluation of Text and Speech Systems, 163–186, Springer. 2007.