Welcome to WordPress. This is your first post. Edit or delete it, then start writing!
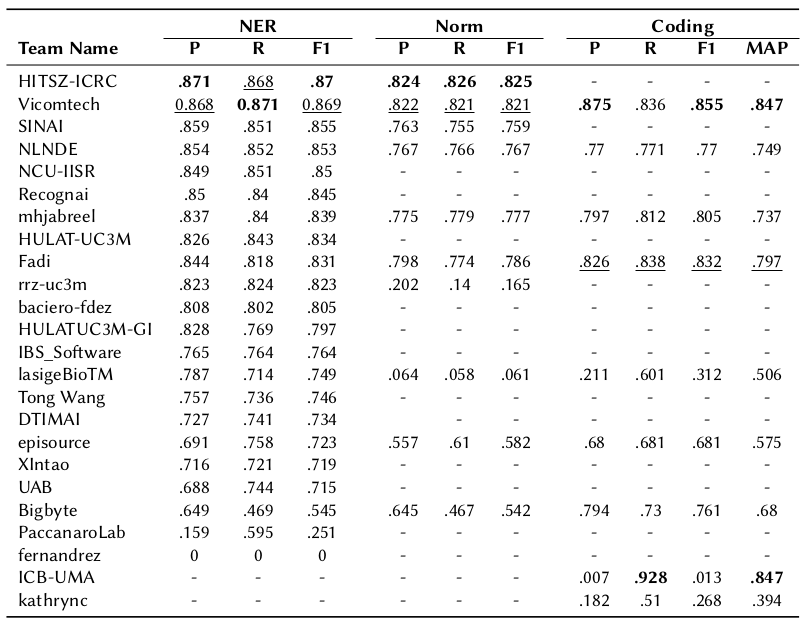
Protected: Results
Publications
All proceedings available at: http://ceur-ws.org/Vol-2664/
- Overview paper:
Named Entity Recognition, Concept Normalization and Clinical Coding: Overview of the Cantemist Track for Cancer Text Mining in Spanish, Corpus, Guidelines, Methods and Results. Antonio Miranda-Escalada, Eulàlia Farré-Maduell, Martin Krallinger. Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2020), CEUR Workshop Proceedings. 303-323 (2020).
URL: http://ceur-ws.org/Vol-2664/cantemist_overview.pdf - Extracting Neoplasms Morphology Mentions in Spanish Clinical Cases through Word Embeddings. Pilar López-Úbeda, Manuel Carlos Díaz-Galiano, María Teresa Martín-Valdivia, Luis Alfonso Ureña-López. Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2020), CEUR Workshop Proceedings. 324-334 (2020).
URL: http://ceur-ws.org/Vol-2664/cantemist_paper1.pdf - NLNDE at CANTEMIST: Neural Sequence Labeling and Parsing Approaches for Clinical Concept Extraction. Lukas Lange, Xiang Dai, Heike Adel, Jannik Strötgen. Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2020), CEUR Workshop Proceedings. 335-346 (2020).
URL: http://ceur-ws.org/Vol-2664/cantemist_paper2.pdf - NCU-IISR: Pre-trained Language Model for CANTEMIST Named Entity Recognition. Jen-Chieh Han, Richard Tzong-Han Tsai. Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2020), CEUR Workshop Proceedings. 347-351 (2020).
URL: http://ceur-ws.org/Vol-2664/cantemist_paper3.pdf - Recognai’s Working Notes for CANTEMIST-NER Track. David Carreto Fidalgo, Daniel Vila-Suero, Francisco Aranda Montes. Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2020), CEUR Workshop Proceedings. 352-357 (2020).
URL: http://ceur-ws.org/Vol-2664/cantemist_paper4.pdf - End-to-End Neural Coder for Tumor Named Entity Recognition. Mohammed Jabreel. Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2020), CEUR Workshop Proceedings. 358-367 (2020).
URL: http://ceur-ws.org/Vol-2664/cantemist_paper5.pdf - Using Embeddings and Bi-LSTM+CRF Model to Detect Tumor Morphology Entities in Spanish Clinical Cases. Sergio Santamaria Carrasco, Paloma Martínez. Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2020), CEUR Workshop Proceedings. 368-375 (2020).
URL: http://ceur-ws.org/Vol-2664/cantemist_paper6.pdf - Tumor Entity Recognition and Coding for Spanish Electronic Health Records. Fadi Hassan, David Sánchez, Josep Domingo-Ferrer. Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2020), CEUR Workshop Proceedings. 376-384 (2020).
URL: http://ceur-ws.org/Vol-2664/cantemist_paper7.pdf - Deep Neural Model with Contextualized-word Embeddings for Named Entity Recognition in Spanish Clinical Text. Renzo Rivera-Zavala, Paloma Martinez. Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2020), CEUR Workshop Proceedings. 385-395 (2020).
URL: http://ceur-ws.org/Vol-2664/cantemist_paper8.pdf - Exploring Deep Learning for Named Entity Recognition of Tumor Morphology Mentions. Gema de Vargas Romero, Isabel Segura-Bedmar. Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2020), CEUR Workshop Proceedings. 396-411 (2020).
URL: http://ceur-ws.org/Vol-2664/cantemist_paper9.pdf - Tumor Morphology Mentions Identification Using Deep Learning and Conditional Random Fields. Utpal Kumar Sikdar, Björn Gambäck, M Krishna Kumar. Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2020), CEUR Workshop Proceedings. 412-421 (2020).
URL: http://ceur-ws.org/Vol-2664/cantemist_paper10.pdf - LasigeBioTM at CANTEMIST: Named Entity Recognition and Normalization of Tumour Morphology Entities and Clinical Coding of Spanish Health-related Documents. Pedro Ruas, Andre Neves, Vitor D.T. Andrade and Francisco M. Couto, Mario Ezra Aragón. Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2020), CEUR Workshop Proceedings. 422-437 (2020).
URL: http://ceur-ws.org/Vol-2664/cantemist_paper11.pdf - A Parallel-Attention Model for Tumor Named Entity Recognition in Spanish. Tong Wang, Yuanyu Zhang, Yongbin Li. Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2020), CEUR Workshop Proceedings. 438-446 (2020).
URL: http://ceur-ws.org/Vol-2664/cantemist_paper12.pdf - A Tumor Named Entity Recognition Model Based on Pre-trained Language Model and Attention Mechanism. Xin Taou, Renyuan Liu, Xiaobing Zhou. Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2020), CEUR Workshop Proceedings. 447-457 (2020).
URL: http://ceur-ws.org/Vol-2664/cantemist_paper13.pdf - Identification of Cancer Entities in Clinical Text Combining Transformers with Dictionary Features. John D Osborne, Tobias O’Leary, James Del Monte, Kuleen Sasse. Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2020), CEUR Workshop Proceedings. 458-467 (2020).
URL: http://ceur-ws.org/Vol-2664/cantemist_paper14.pdf - ICB-UMA at CANTEMIST 2020: Automatic ICD-O Coding in Spanish with BERT. Guillermo López-García, José Manuel Jerez, Nuria Ribelles, Emilio Alba, Francisco Javier Veredas. Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2020), CEUR Workshop Proceedings. 468-476 (2020).
URL: http://ceur-ws.org/Vol-2664/cantemist_paper15.pdf - Automatic ICD Code Classification with Label Description Attention Mechanism. Kathryn Chapman, Günter Neumann. Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2020), CEUR Workshop Proceedings. 477-488 (2020).
URL: http://ceur-ws.org/Vol-2664/cantemist_paper16.pdf - Vicomtech at CANTEMIST 2020. Aitor García-Pablos, Naiara Perez, Montse Cuadros. Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2020), CEUR Workshop Proceedings. 489-498 (2020).
URL: http://ceur-ws.org/Vol-2664/cantemist_paper17.pdf - A Joint Model for Medical Named Entity Recognition and Normalization. Ying Xiong, Yuanhang Huang, Qingcai Chen, Xiaolong Wang, Yuan Nic, Buzhou Tang. Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2020), CEUR Workshop Proceedings. 499-504 (2020).
URL: http://ceur-ws.org/Vol-2664/cantemist_paper18.pdf - Clinical NER using Spanish BERT Embeddings. Ramya Vunikili, Supriya H N, Vasile George Marica, Oladimeji Farri. Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2020), CEUR Workshop Proceedings. 505-511 (2020).
URL: http://ceur-ws.org/Vol-2664/cantemist_paper19.pdf
The proceedings of the previous IberLEF2019 are online at http://ceur-ws.org/Vol-2421/
Working notes format
The working notes style is available via our proceedings volume template at
http://ceur-ws.org/Vol-XXX/ (we will use single-column format as in previous years).
Overleaf users can clone the style from
https://www.overleaf.com/read/gwhxnqcghhdt
Offline versions for LaTeX and DOCX are available from”
http://ceur-ws.org/Vol-XXX/CEURART.zip
Additionally we plan to prepare a journal special issue on the CANTEMIST task overview, corpus and results together with participating technical team systems descriptions in a Q1 journal.
Workshop
Cantemist (CANcer TExt Mining Shared Task) will be part of the IberLEF (Iberian Languages Evaluation Forum) 2020 evaluation campaign at the SEPLN 2020
36th Annual SEPLN Congress (September 23rd to 25th 2020, Málaga)
IberLEF aims to foster the research community to define new challenges and obtain cutting-edge results for the Natural Language Processing community, involving at least one of the Iberian languages: Spanish, Portugueses, Catalan, Basque or Galician. Accordingly, several shared-tasks challenges are proposed.
IberLEF 2020: https://sites.google.com/view/iberlef2020/
SEPLN 2020: http://sepln2020.sepln.org/index.php/en/iberlef-en/
Register for IberLEF and SEPLN here: http://sepln2020.sepln.org/index.php/registro/
All Cantemist talks will be available on YouTube: https://www.youtube.com/playlist?list=PL5uSCzf1azhC24g5dsp5eVMp8BZFWCraX.
| Local Time (CEST) - September 22nd, 2020 | Title | Presenter | Affiliation | More info |
|---|---|---|---|---|
| 6:40 pm | Named Entity Recognition, Concept Normalization and Clinical Coding: Overview of the Cantemist Track for Cancer Text Mining in Spanish, Corpus, Guidelines, Methods and Results | Antonio Miranda-Escalada | Barcelona Supercomputing Center, Spain | TBD |
| 7:00 pm | A Joint Model for Medical Named Entity Recognition and Normalization | Ying Xiong | Xili university town, China | TBD |
| 7:05 pm | Vicomtech at CANTEMIST 2020 | Naiara Pérez | Vicomtech, Spain | TBD |
| 7:10 pm | Extracting Neoplasms Morphology Mentions in Spanish Clinical Cases through Word Embeddings | Pilar López-Úbeda | University of Jaén, Spain | video |
| 7:15 pm | NLNDE at CANTEMIST: Neural Sequence Labeling and Parsing Approaches for Clinical Concept Extraction | Lukas Lange | Bosch Center for Artificial Intelligence, Germany | TBD |
| 7:20 pm | Tumor Entity Recognition and Coding for Spanish Electronic Health Records | Fadi Hassan | Universitat Rovira i Virgili, Spain | TBD |
| 7:25 pm | ICB-UMA at CANTEMIST 2020: Automatic ICD-O Coding in Spanish with BERT | Guillermo López-García | Universidad de Málaga, Spain | TBD |
| 7:30 pm | Conclusions and wrapup | Antonio Miranda-Escalada | Barcelona Supercomputing Center, Spain | - |
FAQ
Email Martin Krallinger to: encargo-pln-life@bsc.es
- Q: What is the goal of the shared task?
The goal is to predict the annotations (or codes) of the documents in the test and background sets. - Q: How do I register?
Here: https://temu.bsc.es/cantemist/?p=3956 - Q: How to submit the results?
We will provide further information in the following days.
Download the example ZIP file.
See Submission page for more info. - Q: Can I use additional training data to improve model performance?
Yes, participants may use any additional training data they have available, as long as they describe it in the working notes. We will ask to summarize such resources in your participant paper. - Q: The task consists of three sub-tasks. Do I need to complete all sub-tasks? In other words, If I only complete a sub-task or two sub-tasks, is it allowed?
Sub-tasks are independent and participants may participate in one, two or the three of them. - Q: How can I submit my results? Can I submit several prediction files for each sub-task?
You will have to create a ZIP file with your predictions file and submit it to EasyChair (further details will be soon released).
Yes, you can submit up to 5 prediction files, all in the same ZIP.
Download the example ZIP file.
See Submission page for more info. - Q: Should prediction files have headings?
No, prediction files should have no headings. - Q: Are all codes and mentions equally weighted?
Yes. However, systems will be evaluated including and excluding 8000/6 mentions. - Q: What version of the eCIE-O-3-1 is in use?
We are using the 2018 version. The table you can download from the official Spanish webpage is not complete. CIE-O allows combining the digits 6th and 7th according to the pathological study and the differentiation degree. That is, not all the combinations of the 6th and 7th characters are shown in the table.
There is a complete list of the valid codes on our webpage. Codes not present in this list will not be used for the evaluation. - Q. What is meant by the /H appended to various codes?
Some tumor mentions contain a relevant modifier not included in the terminology for this concept. Then, we append /H to the code.
For example, in the file cc_onco158, we have the codes 8000/1 and 8000/1/H.
8000/1 corresponds to a mention of neoplasm (“neoplasia”, in Spanish).
In the 8000/1/H case, the mention is (in Spanish) “neoplasia de estirpe epitelial”. The modifier “estirpe epitelial” is present in the ICD-O terminology for many tumors. However, it is not present to modify specifically the code 8000/1. Then, we consider it a relevant modifier and add the /H.
Schedule
| Event | Date | Link |
|---|---|---|
| Sample Set release | April, 28 | Sample set |
| Train Set Release and guidelines publication | June, 5 | Dataset and annotation guidelines |
| Development Set Release | June, 12 | Dataset |
| Test and Background Set Release | July, 3 | Dataset |
| End of evaluation period. Predictions submission deadline | August, 5, 23:59 CEST | Submission tutorial |
| Evaluation delivery and Test Set with Gold Standard annotations | August, 7 | Dataset |
| Working Notes deadline | August, 14, 23:59 CEST | Easychair |
| Working Notes Corrections deadline | August, 25 | |
| Camera-ready submission deadline | September, 1 | |
| IberLEF @ SEPLN 2020 | September, 22, from 16h to 20h | IberLEF |
Evaluation
Evaluation will be done by comparing the automatically generated results to the results generated by manual annotation of experts.
The primary evaluation metric for all three sub-tracks will consist of micro-averaged precision, recall and F1-scores:

The used evaluation scripts together with a Readme file with instructions will be available on GitHub to enable systematic fine-tuning and improvement of results on the provided training/development data using by participating teams.
For the CANTEMIST-CODING sub-track we also apply a standard ranking metric: Mean Average Precision (MAP) for evaluation purposes.
MAP (Mean Average Precision) is an established metric used for ranking problems.
All metrics will be computed including and excluding mentions with 8000/6 code.
Registration
To register, please fill in the registration form:
Premios
TBD
Awards
CANTEMIST: CANcer TExt Mining Shared Task will be part of the IberLEF 2020 evaluation campaign at the SEPLN 2020
The Plan for Promoting Language Technologies (Plan TL) aims to promote the development of natural language processing, machine translation and conversational systems in Spanish. In the line, through its collaboration with the Barcelona Supercomputing Center (BSC) to promote activities for specialized on language technologies applied to health an biomedicine , we announce the call for shared task awards detailed below.
Registration: Fill in an online registration form.
Deadlines for submission: August, 3
Evaluation: The evaluation of the automatic predictions for this task will have three different scenarios or sub-tasks:
- CANTEMIST-NER. Main evaluation metric: F-score.
- CANTEMIST-NORM. Main evaluation metric: F-score.
- CANTEMIST-CODING. Main evaluation metric: Mean Average Precision.
For further details on the evaluation of the sub-tasks, please refer to Evaluation.
Task organizers: This task has been coordianted by the OT de Sanidad of the Plan TL.
Scientific committee evaluator: Please refer to Scientific Committee.
Selection of winners: The first 3 classified in the tasks will be selected as finalists to receive prizes. System evaluations will be performed according to the evaluation criteria described in Evaluation.
Budget: The total budget for this call is 5100 euros.
The first classified in each of the sub-task will receive a prize of 1,000 euros, the second classified in each of the sub-task will receive a prize of 500 euros and the third classified in each of the sub-task will receive a prize of 200 euros.
Contact: For further details, please refer to encargo-pln-life@bsc.es
Official Cantemist results