| Date | Event | Link |
|---|---|---|
| January 13, 2020 | Train set release | Training set |
| January 13, 2020 | Development set release | Development set |
| January 13, 2020 | Additional sets release | Additional corpora |
| January 20, 2020 | Evaluation Script release | Evaluation Script |
| March 2, 2020 | Test set release (includes Background set) | Test set |
| April 28-May 1, 2020 | MIE2020 Workshop | MIE2020 Programme |
| May 10, 2020 | End of evaluation period: Participant results submissions | Submission |
| May 12, 2020 | Results notified. Test set with GS annotations release | Test set GS |
| July 17, 2020 | Participants’ working notes papers submitted | Easychair submission |
| August 14, 2020 | Notification of acceptance participant papers | TBA |
| August 28, 2020 | Camera ready paper submission | TBA |
| September 22-25, 2020 | CLEF 2020 | CLEF 2020 conference |
Publications

We would like to inform you that CodiEsp’s proceedings will be part of the CLEF 2020 conference. In particular, it will be part of the CLEF eHealth series. The schedule is therefore adjusted according to the CLEF schedule. CodiEsp’s proceedings will also be adjusted to CLEF requirements and they will be published in Springer LNCS Series. As soon as further information about proceedings is ready on the CLEF webpage, it will be published here.
Paper submission schedule:
| Date | Event | Link |
|---|---|---|
| July 17, 2020 | Participants’ working notes papers submitted | https://easychair.org/conferences/?conf=clef2020 |
| August 14, 2020 | Notification of acceptance participant papers | TBA |
| August 28, 2020 | Camera ready paper submission | TBA |
| September 22-25, 2020 | CLEF 2020 | https://clef2020.clef-initiative.eu/index.php |
Proceedings Details:
- Extension: TBD
- Structure: TBD
- Link to further details: TBD
- Last year Proceedings: https://link.springer.com/book/10.1007/978-3-030-28577-7
Protected: Results
Publications

We would like to inform you that CodiEsp’s proceedings will be part of the CLEF 2020 conference. In particular, it will be part of the CLEF eHealth series. The schedule is therefore adjusted according to the CLEF schedule. CodiEsp’s proceedings will also be adjusted to CLEF requirements and they will be published in Springer LNCS Series. As soon as further information about proceedings is ready on the CLEF webpage, it will be published here.
Paper submission schedule:
| Date | Event | Link |
|---|---|---|
| July 17, 2020 | Participants’ working notes papers submitted | https://easychair.org/conferences/?conf=clef2020 |
| August 14, 2020 | Notification of acceptance participant papers | TBA |
| August 28, 2020 | Camera ready paper submission | TBA |
| September 22-25, 2020 | CLEF 2020 | https://clef2020.clef-initiative.eu/index.php |
Proceedings Details:
- Submission instructions: https://temu.bsc.es/codiesp/wp-content/uploads/2020/06/codiesp-codiesp-working-notes-submission-instructions.pdf
- Structure: LaTex template
- Last year Proceedings: https://link.springer.com/book/10.1007/978-3-030-28577-7
Task Overview cite
@InProceedings{CLEFeHealth2020Task1Overview,
author={Antonio Miranda-Escalada and Aitor Gonzalez-Agirre and Jordi Armengol-Estapé and Martin Krallinger},
title="Overview of automatic clinical coding: annotations, guidelines, and solutions for non-English clinical cases at CodiEsp track of {CLEF eHealth} 2020",
booktitle = {{Working Notes of Conference and Labs of the Evaluation (CLEF) Forum}},
series = {{CEUR} Workshop Proceedings},
year = {2020}, }
Lab Overview cite
@InProceedings{CLEFeHealth2020LabOverview,
author={Lorraine Goeuriot and Hanna Suominen and Liadh Kelly and Antonio Miranda-Escalada and Martin Krallinger and Zhengyang Liu and Gabriella Pasi and Gabriela {Saez Gonzales} and Marco Viviani and Chenchen Xu},
title="Overview of the {CLEF eHealth} Evaluation Lab 2020",
booktitle = {{Experimental IR Meets Multilinguality, Multimodality, and Interaction: Proceedings of the Eleventh International Conference of the CLEF Association (CLEF 2020) }},
series = {LNCS Volume number: 12260},
year = {2020},
editor = {Avi Arampatzis and Evangelos Kanoulas and Theodora Tsikrika and Stefanos Vrochidis and Hideo Joho and Christina Lioma and Carsten Eickhoff and Aurélie Névéol and Linda Cappellato and Nicola Ferro}
}
Workshops
MIE2020
CodiEsp setting and results will be presented at the workshop First Multilingual clinical NLP workshop (MUCLIN) at MIE2020. This year, MIE is virtual thanks to the collaboration of EFMI. Please, register at https://us02web.zoom.us/webinar/register/WN_xSrKgnjsQhGP_ZUsQUS3fQ
This workshop will have two parts:
First, there will be a presentation of the shared task overview and proposed approaches.
Then, there will be a 30 minutes panel discussion with experts on the role of the shared tasks to promote clinical NLP, resources, tools, evaluation methods.
See EFMI program.
See MUCLIN program.
CLEF eHealth
CodiEsp is included in the 2020 Conference and Labs of the Evaluation Forum, this year, an online-only event.
Participants’ working notes will be published in the CEUR-WS proceedings (http://ceur-ws.org/). Task overview paper will also be published in the CEUR-WS proceedings.
@InProceedings{CLEFeHealth2020Task1Overview,
author={Antonio Miranda-Escalada and Aitor Gonzalez-Agirre and Jordi Armengol-Estapé and Martin Krallinger},
title="Overview of automatic clinical coding: annotations, guidelines, and solutions for non-English clinical cases at CodiEsp track of {CLEF eHealth} 2020",
booktitle = {{Working Notes of Conference and Labs of the Evaluation (CLEF) Forum}},
series = {{CEUR} Workshop Proceedings},
year = {2020},
}
Since CodiEsp is part of CLEF eHealth lab, lab overview paper will be published in the Springer LNCS proceedings.
@InProceedings{CLEFeHealth2020LabOverview,
author={Lorraine Goeuriot and Hanna Suominen and Liadh Kelly and Antonio Miranda-Escalada and Martin Krallinger and Zhengyang Liu and Gabriella Pasi and Gabriela {Saez Gonzales} and Marco Viviani and Chenchen Xu},
title="Overview of the {CLEF eHealth} Evaluation Lab 2020},
booktitle = {{Experimental IR Meets Multilinguality, Multimodality, and Interaction: Proceedings of the Eleventh International Conference of the CLEF Association (CLEF 2020)
}},
series = {LNCS Volume number: 12260},
year = {2020},
editor = {Avi Arampatzis and Evangelos Kanoulas and Theodora Tsikrika and Stefanos Vrochidis and Hideo Joho and Christina Lioma and Carsten Eickhoff and Aurélie Névéol and Linda Cappellato andNicola Ferro},
}
Journal Special Issue
The planned workshop functions as a venue for the different types of contributors, mainly task providers and solution providers, to meet together and exchange their experiences.
We expect that investigation on the topics of the task will continue after the workshop, based on new insights obtained through discussions during the workshop.
As a venue to compile the results of the follow-up investigation, a journal special issue will be organized to be published a few months after the workshop. The specific journal will be announced after negotiation with publishers.
Contact and FAQ
Email Martin Krallinger to: encargo-pln-life@bsc.es
FAQ
- How to submit the results?
Results will be submitted through EasyChair. We will provide further submission information in the following days. - Can I use additional training data to improve model performance?
Yes, participants may use any additional training data they have available, as long as they describe it in the working notes. We will ask to summarize such resources in your participant paper foreHealth CLEF and the short survey we will share with all teams after the challenge. - The task consists of three sub-tasks. Do I need to complete all sub-tasks? In other words, If I only complete a sub-task or two sub-tasks, is it allowed?
Sub-tasks are independent and participants may participate in one, two or the three of them. - Are there unseen codes in the test set?
Yes, there may be unseen codes in the test set. We performed a random split of training, validation and test. 500 documents were to train, 250 to validation and 250 to test. - Why is number of training and development dataset (500 and 250) low in comparison with testing data (circa 3000)?
It is actually not. There are 250 test set documents. However, we have added the background set (circa 2700), to prevent manual predictions. Systems will only be evaluated on the 250 test set documents. - How can I submit my results? Can I submit several prediction files for each sub-task?
You will have to create a ZIP file with your predictions file and submit it to EasyChair (see step-by-step guide).
Yes, you can submit up to 5 prediction files, all in the same ZIP. - Should prediction files have headings?
No, prediction files should have no headings. See more information about prediction file format at the submission page.
Schedule
TBD
Evaluation
The CodiEsp evaluation script can be downloaded from GitHub.
Please, make sure you have the latest version.
Participants will submit their predictions for the test set and the background set. Both will be released together so that they cannot be separated to make sure that participating teams will not be able to do manual corrections and also that these systems are able to scale to larger data collections. However, predictions will only be evaluated for the test set.
CodiEsp-D and CodiEsp-P: MAP
For sub-tracks CodiEsp-D and CodiEsp-P, participants will submit their coding predictions ranked. For every document, a list of possible codes will be submitted ordered by confidence or relevance (codes not in the list of valid codes will be ignored). Then, since these sub-tracks are ranking competitions, they will be evaluated on a standard ranking metric: Mean Average Precision (MAP).
MAP is the most established metric in ranking problems. It stands for Mean Average Precision, where the Average Precision represents the average precision of a document at every position in the ranked codes. That is, precision is computed considering only the first ranked code; then, it is computed considering the first two codes, and so on. Finally, precision values are averaged over the number of codes in the gold standard (the relevant number of codes):
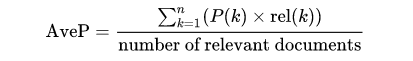
MAP is the most standard ranking metric among TREC community and it has shown good discrimination and stability [1]. Individual average precisions are equivalent, in the limit, to the area under the precision-recall curve; therefore, MAP represents the mean of the areas under the precision-recall curve.
It favors systems that return relevant documents fast [2] since those systems would have a higher average precision for every clinical case of the test set. Finally, contrary to other ranked evaluation metrics, it is easy to understand if precision and recall concepts are already understood; it takes into account all relevant retrieved documents; and information is stored in a single point, which eases comparison among systems.
CodiEsp-X: F-score
For the Explainable AI sub-track, the explainability of the systems will be considered, in addition to their performance on the test set.
To evaluate both explainability and performance of a system, systems have to provide a reference in the text that supports the code assignment (codes not in the list of valid codes will be ignored). That reference is cross-checked with the true reference used by expert annotators. Only correct codes with correct references are valid. Then, Precision, Recall, and F1-score are used to evaluate system performance (F-score is the primary metric).
Precision (P) = true positives/(true positives + false positives)
Recall (R) = true positives/(true positives + false negatives)
F-score (F1) = 2*((P*R)/(P+R))
Special cases:
- In case one single code has several references in the Gold Standard file, acknowledging only one is enough.
- For discontinuous references, the metric considers that the reference starts at the start position of the first fragment of the reference. Equivalently, the reference is considered to end at the final position of the last fragment of the reference.
References
[1] Christopher D. Manning, Prabhakar Raghavan and Hinrich Schütze, Introduction to Information Retrieval, Cambridge University Press. 2008.
[2] L. Dybkjær et al. (eds.), Evaluation of Text and Speech Systems, 163–186, Springer. 2007.
Registration
Go to the CLEF 2020 webpage http://clef2020-labs-registration.dei.unipd.it/ webpage and follow these steps:
- Click on Subscribe.
2. Fill in your personal information.

3. Click on CLEF eHealth Task 1.

4. Submit.

Awards
The Plan for the Advancement of Language Technology (Plan TL) aims to promote the development of natural language processing, machine translation and conversational systems in Spanish and co-official languages. In the framework of this plan, we announce the call for the shared task awards detailed below.
The first classified in each of the sub-task will receive a prize of 1,000 euros, the second classified in each of the sub-task will receive a prize of 500 euros and the third classified in each of the sub-task will receive a prize of 200 euros.
Registration: Fill in an online registration form. See Registration for further details.
Deadlines for submission: The deadline for submission is May 3, 2020, and the resolution of awards will be after CLEF conference on September 22-25, 2020. For further details, please refer to the Schedule.
Evaluation: The evaluation of the automatic predictions for this task will have three different scenarios or sub-tasks:
- CodiEsp-D. Main evaluation metric: Mean Average Precision.
- CodiEsp-P. Main evaluation metric: Mean Average Precision.
- CodiEsp-X. Main evaluation metric: F-score.
For further details on the evaluation of the sub-tasks, please refer to Evaluation.
Selection of winners: The first 3 classified in the tasks will be selected as finalists to receive prizes. System evaluations will be performed according to the evaluation criteria described in Evaluation.
Contact: For further details, please refer to Martin Krallinger at encargo-pln-life@bsc.es

Official CodiEsp results
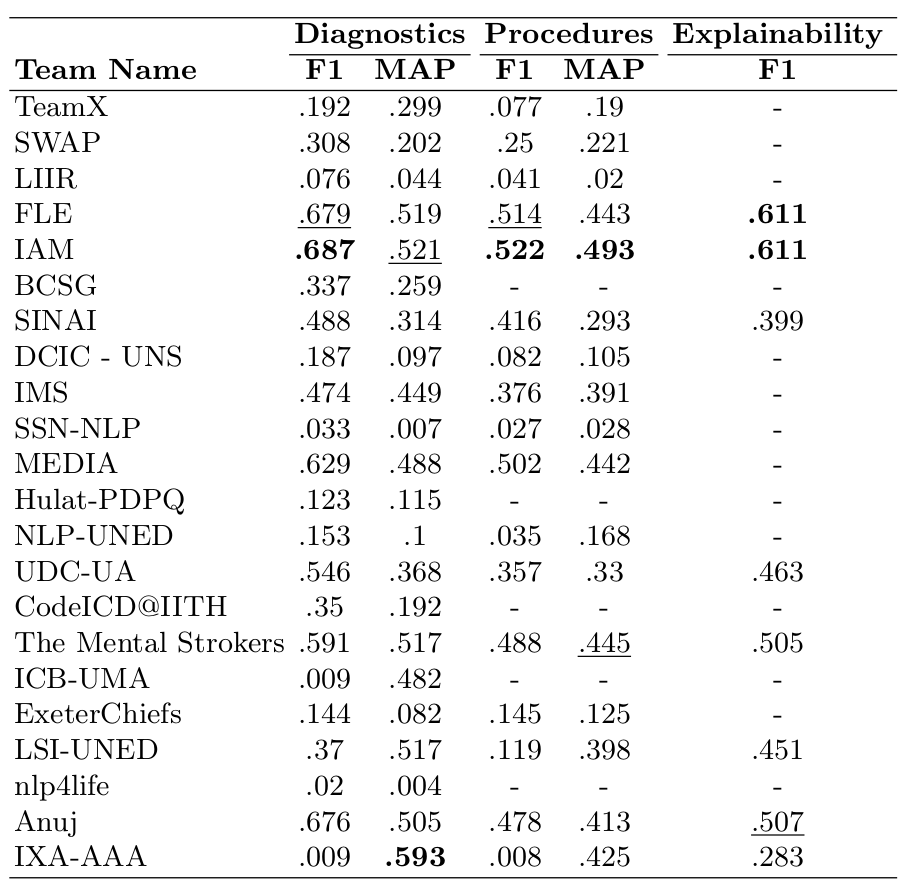
**IAM Explainability results are unofficial (see overview paper for more information)