The CodiEsp evaluation script can be downloaded from GitHub.
Please, make sure you have the latest version.
Example 1: CodiEsp-D or CodiEsp-P
Evaluate the system output pred_D.tsv against the gold standard gs_D.tsv (both inside toy_data subfolders).
$> python3 codiespD_P_evaluation.py -g gold/toy_data/gs_D.tsv -p system/toy_data/pred_D.tsv -c codiesp_codes/codiesp-D_codes.tsv MAP estimate: 0.444
Example 2: CodiEsp-X
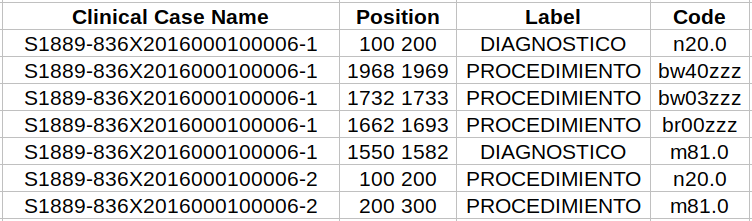
Evaluate the system output pred_X.tsv against the gold standard gs_X.tsv (both inside toy_data subfolders).
$> python3 codiespX_evaluation.py -g gold/toy_data/gs_X.tsv -p system/toy_data/pred_X.tsv -cD codiesp_codes/codiesp-D_codes.tsv -cP codiesp_codes/codiesp-P_codes.tsv ----------------------------------------------------- Clinical case name Precision ----------------------------------------------------- S0000-000S0000000000000-00 nan ----------------------------------------------------- S1889-836X2016000100006-1 0.625 ----------------------------------------------------- codiespX_evaluation.py:248: UserWarning: Some documents do not have predicted codes, document-wise Precision not computed for them. Micro-average precision = 0.556 ----------------------------------------------------- Clinical case name Recall ----------------------------------------------------- S0000-000S0000000000000-00 nan ----------------------------------------------------- S1889-836X2016000100006-1 0.455 ----------------------------------------------------- codiespX_evaluation.py:260: UserWarning: Some documents do not have Gold Standard codes, document-wise Recall not computed for them. Micro-average recall = 0.385 ----------------------------------------------------- Clinical case name F-score ----------------------------------------------------- S0000-000S0000000000000-00 nan ----------------------------------------------------- S1889-836X2016000100006-1 0.526 ----------------------------------------------------- codiespX_evaluation.py:271: UserWarning: Some documents do not have predicted codes, document-wise F-score not computed for them. codiespX_evaluation.py:274: UserWarning: Some documents do not have Gold Standard codes, document-wise F-score not computed for them. Micro-average F-score = 0.455 __________________________________________________________ MICRO-AVERAGE STATISTICS: Micro-average precision = 0.556 Micro-average recall = 0.385 Micro-average F-score = 0.455
Contact for technical issues
Antonio Miranda-Escalada (antonio.miranda@bsc.es)