MedProcNER Shared Task Homepage
The MedProcNER Track is organized by the Barcelona Supercomputing Center’s NLP for Biomedical Information Analysis group and promoted by Spanish and European projects such as Plan de Impulso de las Tecnologías del Lenguaje (Plan TL), DataTools4Heart, AI4HF, BARITONE and AI4ProfHealth.
What is MedProcNER?
MedProcNER stands for MEDical PROCedure Named Entity Recognition. It is a shared task and set of resources focused on the detection, normalization and indexing of clinical procedures in medical documents in Spanish.
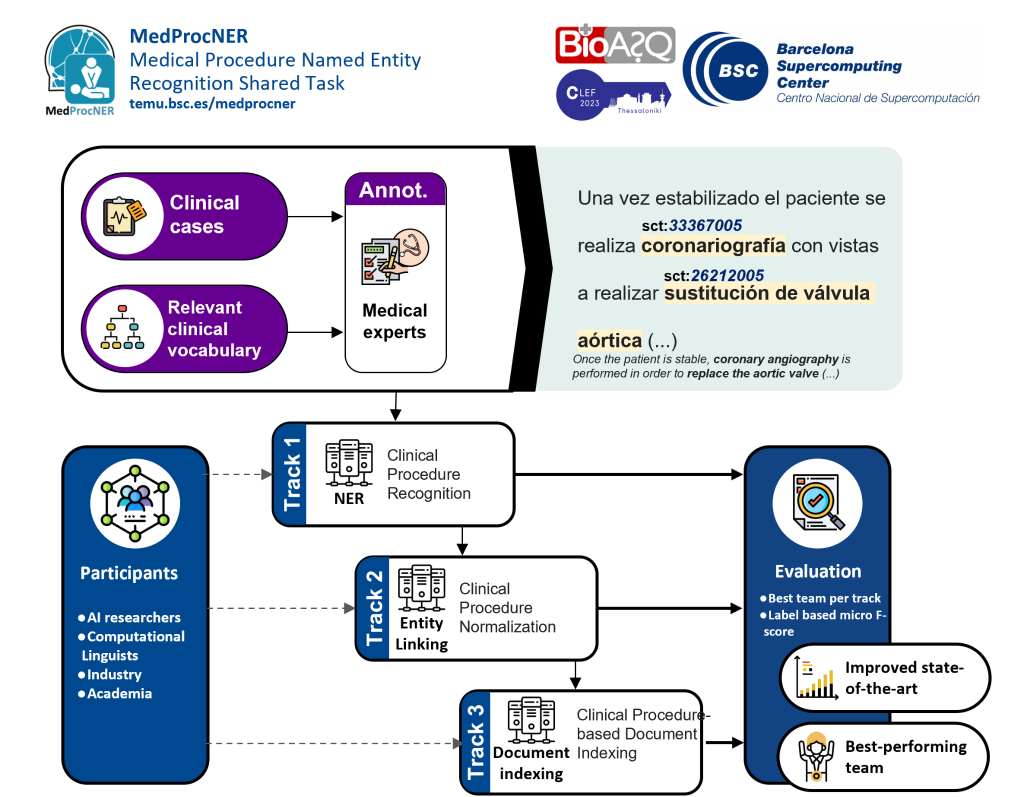
For more information about the MedProcNER task, check the Task Info tab, which includes the Motivation, Subtasks, Schedule, Registration and Submission pages.
To learn more about the MedProcNER corpus and how it was annotated, check the Data tab, including the Corpus Description, Annotation Guidelines (with example annotations and screenshots) and Download pages.
MedProcNER will be held as part of the BioASQ Workshop in the CLEF 2023 conference. For more information about them, check the Workshop tab.
MedProcNER is organized by the Barcelona Supercomputing Center’s NLP for Biomedical Information Analysis group (formerly Text Mining Unit).
Important information
- The complete MedProcNER dataset, as well as the SNOMED gazetteer, MeSH cross-mappings and Silver Standard multilingual version in 9 languages are now available in Zenodo.
- The BioASQ and MedProcNER overviews, as well as participant papers, are now available in the Publications tab.
Related resources
At the NLP for Biomedical Information Analysis group (formerly Text Mining Unit), one of our missions is the open publication of datasets to train and benchmark biomedical information extraction, normalization and indexing systems. For that reason, we have released multiple datasets as part of shared tasks over the years. If you are interested in MedProcNER, you might want to take a look at some of our resources and competitions about:
- Clinical content extraction: DisTEMIST (diseases), CANTEMIST (tumour morphology), CodiEsp (coding to ICD), PharmaCoNER (chemicals and proteins)
- Sociodemographic content extraction: MEDDOPLACE (locations and more — new this year!) MEDDOCAN (sensitive data), MEDDOPROF (occupations)
- Information extraction in social media: SocialDisNER (diseases), ProfNER (occupations)
- Linguistic aspects: BARR1 and BARR2 (abbreviation resolution)
- Machine Translation: ClinSpEn (EN<->ES clinical content translation)
Schedule
| Event | Date (Midnight CEST) |
|---|---|
| MedProcNER Annotation Guidelines Release | February 2023 |
| MedProcNER Train Set Subtask 1 (NER) Release | April 11th 2023 |
| MedProcNER Train Set Subtask 2+3 (Norm+Indexing) Release | May 2nd 2023 |
| MedProcNER Gazetteer Release | May 2nd 2023 |
| MedProcNER Additional Dataset Release | TBD |
| MedProcNER Test Set Release | May 2nd 2023 |
| Participant Test Predictions Deadline | May 15th 2023 ("Anywhere on Earth") |
| Participant Evaluation Result Release | May 25th 2023 |
| Submission of Participant Papers Deadline | June 5th 2023 |
| Notification of Acceptance of Participant Papers | June 23rd 2023 |
| Submission of Camera-ready Participant Papers Deadline | July 7th 2023 |
| BioASQ @ CLEF2023 | September 18th-21st 2023 |