ProfNER-ST: Identification of professions & occupations in Health-related Social Media
Generated resources
- Data: Gold Standard, Silver Standard (TBP) & Annotation Guidelines
- Conference Proceedings
- YouTube presentations
- Participant codes
Please, cite:
Miranda-Escalada, A., Farré-Maduell, E., Lima-López, S., Gascó, L., Briva-Iglesias, V., Agüero-Torales, M., & Krallinger, M. (2021, June). The profner shared task on automatic recognition of occupation mentions in social media: systems, evaluation, guidelines, embeddings and corpora. In Proceedings of the Sixth Social Media Mining for Health (# SMM4H) Workshop and Shared Task (pp. 13-20).
@inproceedings{miranda2021profner,
title={The profner shared task on automatic recognition of occupation mentions in social media: systems, evaluation, guidelines, embeddings and corpora},
author={Miranda-Escalada, Antonio and Farr{\'e}-Maduell, Eul{`a}lia and Lima-L{\'o}pez, Salvador and Gasc{\'o}, Luis and Briva-Iglesias, Vicent and Ag{\"u}ero-Torales, Marvin and Krallinger, Martin},
booktitle={Proceedings of the Sixth Social Media Mining for Health (# SMM4H) Workshop and Shared Task},
pages={13--20},
year={2021}}
SocialDisNer Track @ SMM4H 2022
For SMM4H 2022 edition we organized the SocialDisNER task on disease detection in tweets. More info here.
Schedule
| Event | Date (UTC) | Link |
|---|---|---|
| Training & Development set release | Dec 15 | Train, dev, test and background sets |
| Validation predictions due [Practice Phase] [Required] | Feb 25 | Codalab |
| Test set release (without annotations) | Mar 1 | Train, dev, test and background sets |
| Test set predictions due [Evaluation Phase] | Mar 4 | Codalab |
| Test set evaluation scores release | Mar 8 | - |
| System descriptions due | Mar 15 | Softconf site |
| Acceptance notification | Apr 1 | - |
| Camera ready system descriptions | Apr 12 | Softconf site |
| SMM4H workshop at NAACL conference | June 6–11 | https://2021.naacl.org/ |
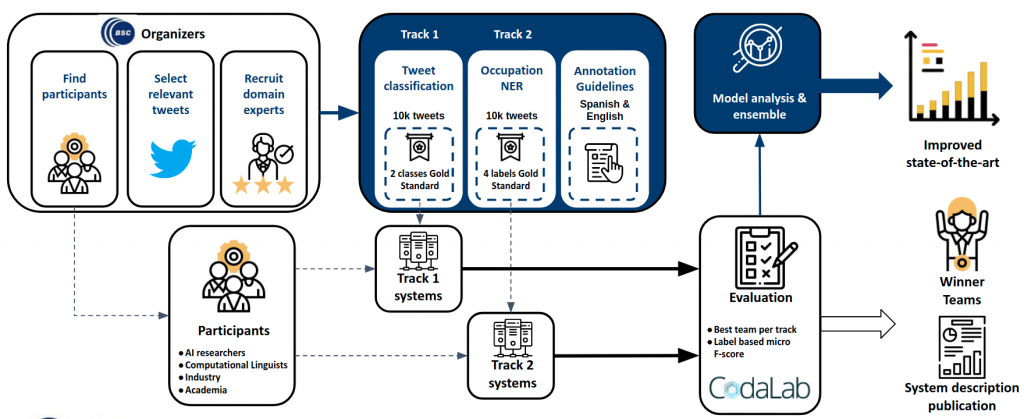
About the task
Identification of professions and occupations (ProfNER) in Spanish. This task will focus on the recognition of professions and occupations from Twitter using data in Spanish after selecting health-relevant content. The aim is to extract professions from social media to enable characterizing health-related issues, in particular in the context of COVID-19 epidemiology as well as mental health conditions.
As for the automatic recognition of professions, we should highlight that some workers are at the forefront of the battle against the COVID-19 pandemic. Detecting vulnerable occupations, be it due to their risk of direct exposure to the virus or due to mental health issues associated with work-related aspects is critical to prepare preventive measures. In case of direct exposures and COVID-19 deaths, data from the UK Office for National Statistics point out that it is important to characterize such at-risk groups, which included not only healthcare workers but also professions such as caregivers, taxi drivers, security guards or retail assistants. The ProfNER shared task will enable training deep learning named entity recognition approaches.
The Social Media Mining for Health Applications (#SMM4H) Shared Task 2021 invites researchers to develop systems to solve health informatics challenges for social media. The seventh track of the task focuses on the identification of professions and occupations in Spanish tweets. Previous versions of the SMM4H have included a similar task on English tweets and this year, the dataset includes sets of tweets in English, Spanish and Russian languages. This webpage is devoted to the Spanish part of this multilingual track (i.e. identification of professions and occupations in Spanish tweets).
There are 2 Spanish sub-tracks:
- Track A – Tweet binary classification. Participants must determine whether a tweet contains a mention of occupation, or not.

- Track B – NER offset detection and classification. Participants must find the beginning and end of occupation mentions and classify them in the corresponding category. The corpus contains 4 mention categories, but participants will only be evaluated in the prediction of 2 of them: PROFESION [profession] and SITUACION_LABORAL [working status].

The SMM4H 2021 general webpage can be accessed here.
#SMM4H is held as part of the 2021 Annual Conference of the North American Chapter of the Association for Computational Linguistics.
Overview Video