MultiClinSum-2 Shared Task
The MultiClinSum-2 Track is organized by the Barcelona Supercomputing Center’s NLP for Biomedical Information Analysis group and promoted by European projects such as DataTools4Heart and AI4HF.
MultiClinSum-2 is a shared task focused on evaluating multilingual automatic summarization systems for clinical documents. Organized by the Barcelona Supercomputing Center’s NLP for Biomedical Information Analysis group and promoted by European projects such as DataTools4Heart and AI4HF, this second edition of the task challenges participants to develop models capable of condensing lengthy clinical narratives into concise summaries while preserving essential diagnostic and clinically relevant information. The task provides multilingual full case-summary pairs across 15 languages: English, Spanish, French, Portuguese, Italian, Russian, Catalan, Norwegian, Danish, Romanian, German, Greek, Dutch, Czech, and Swedish, combining large-scale data from PubMed Central with carefully curated native-language case reports from the biomedical literature. MultiClinSum-2 offers a comprehensive benchmark for assessing multilingual clinical summarization performance in the biomedical domain.
For more information about the task, check the Task Info tab, which includes the Motivation, Subtasks, Schedule, Registration and Submission pages. To learn more about the creation of the task corpus, check the Data tab.
MultiClinSum-2 will be held as part of the BioASQ Workshop in the CLEF 2026 conference. For more information about them, check the Workshop tab.
Registration
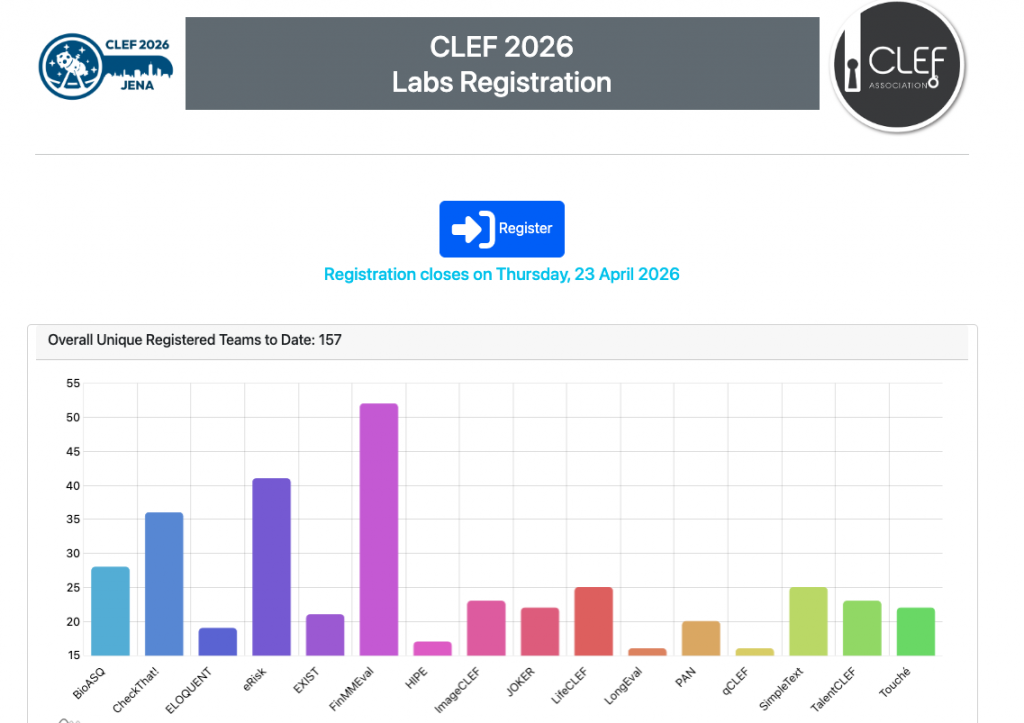
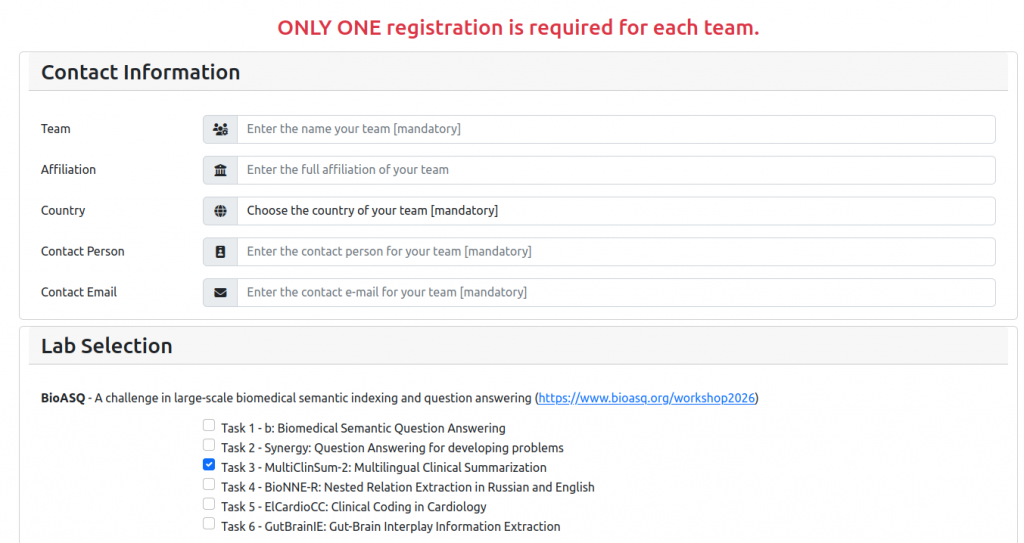
You can register for the MultiClinSum-2 task of the BioASQ 14 Workshop using the official CLEF registration link. Make sure that you select the “Task 3 – MultiClinSum-2: Multilingual Clinical Summarization” option!
Registration steps:
- Click on Register in the registration link:
2. Make sure you fill in all the contact information and select the BioASQ Task 3 – MultiClinSum-2: Multilingual Clinical Summarization option.
Related resources
At the NLP for Biomedical Information Analysis group (formerly Text Mining Unit), one of our missions is the open publication of datasets to train and benchmark biomedical information extraction, normalization and indexing systems. For that reason, we have released multiple datasets as part of shared tasks over the years. If you are interested in MultiClinSUM2, you might want to take a look at some of our resources and competitions about:
- MultiClinSum (Multilingual Summarization of clinical content — first edition of this task!)
- Annotation projection / Multilingual NER: MultiClinAI (new task this year!)
- Clinical content extraction: DisTEMIST (diseases), MedProcNER/ProcTEMIST (clinical procedures), SympTEMIST (signs and findings), CANTEMIST (tumour morphology), CodiEsp (coding to ICD), PharmaCoNER (chemicals and proteins), LivingNER (species and humans), MultiCardioNER (diseases and medications, includes the DrugTEMIST corpus as well as cardiology-specific data)
- Socio-demographic / Social Determinants of Health content extraction: MEDDOPLACE (locations and more) MEDDOCAN (sensitive data), MEDDOPROF (occupations), ToxHabits (extraction of substance use-related content)
- Information extraction in social media: SocialDisNER (diseases), ProfNER (occupations)
- Linguistic aspects: BARR1 and BARR2 (abbreviation resolution)
- Machine Translation: ClinSpEn (EN<->ES clinical content translation)