For this task, we have prepared a synthetic corpus of clinical cases enriched with PHI expressions, named the MEDDOCAN corpus. This MEDDOCAN corpus of 1,000 clinical case studies was selected manually by a practicing physician and augmented with PHI phrases by health documentalists, adding PHI information from discharge summaries and medical genetics clinical records.
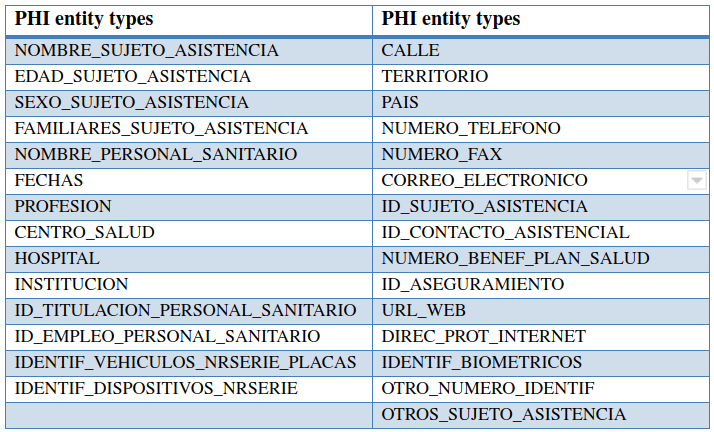
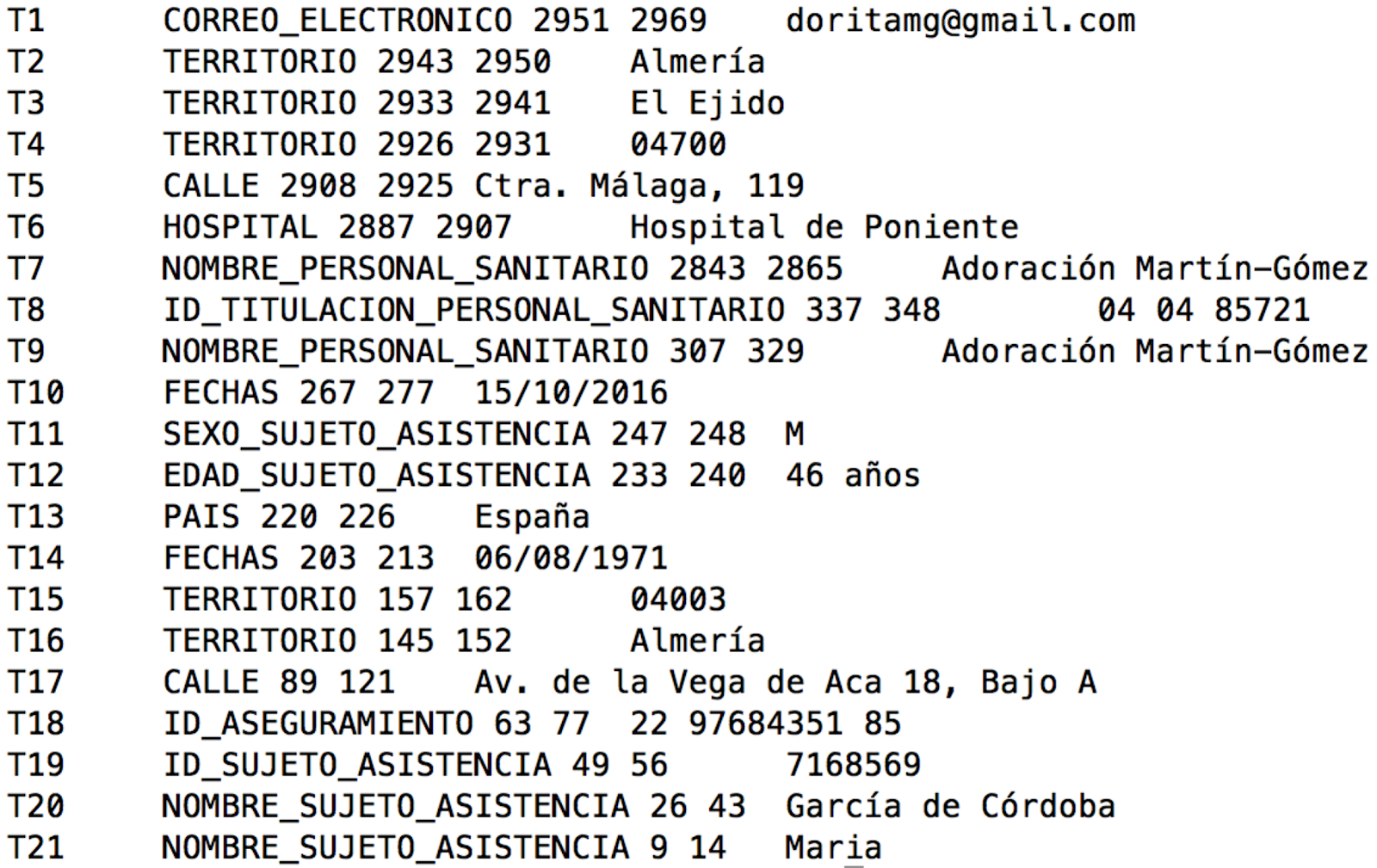
The final collection of 1,000 clinical cases that make up the corpus had around 33 thousand sentences, with an average of around 33 sentences per clinical case. The MEDDOCAN corpus contains around 495 thousand words, with an average of 494 words per clinical case, slightly less than for the records of the i2b2 de-identification longitudinal corpus (617 tokens per record). The MEDDOCAN corpus will be distributed in plain text in UTF8 encoding, where each clinical case would be stored as a single file, while PHI annotations will be released in the popular BRAT format, which makes visualization of results straightforward, as you can see in Figure 1.

The entire MEDDOCAN corpus has been randomly sampled into three subsets, the training, development and test set. The training set comprises 500 clinical cases, and the development and test set 250 clinical cases each. Together with the test set release, we will release an additional collection of 2,000 documents (background set) to make sure that participating teams will not be able to do manual corrections and also promote that these systems would potentially able to scale to larger data collections.
For this task we also prepared a conversion script (see Resources) between the BRAT annotation format and the annotation format used by the previous i2b2 effort, to make comparison and adaptation of previous systems used for English texts easier.