In this section, we show examples of how the evaluation will be carried out to make it clearer. For the following examples, we will consider that this set of MEDDOCAN tags is our Gold Standard (GS):

This GS file is in i2b2 format. We have a DATE entity, a CONTACT entity, four LOCATION entities, and a NAME entity. Each entity tag is composed of the ID, the START and END offsets, the text snippet between the previous offsets, the entity TYPE and a COMMENT.
NOTE: The ID, TEXT, and COMMENT fields are not used for any of the evaluation metrics. The number in the ID field and the COMMENT field are arbitrary, and the evaluation of the TEXT field is implicit in the offset evaluation, as the text is the same for the GS and the systems.
Sub-track 1: NER offset
In this sub-track we want to match exactly the beginning and end locations of each PHI entity tag, as well as detecting correctly the annotation type. The following system annotations will be accepted by the evaluation script even if the numbers on the ID fields are different, and additional comments are included.

For this example the scores obtained by this system are the following:
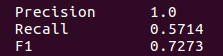
Precisión has been computed dividing true positives (4) by the sum of true positives and false positives (0), scoring 4/(4+0) = 1.0. Recall has been computed dividing true positives by the sum of true positives and false negative (3: Tags with IDs T1, T5, and T7 in the GS), scoring 4/(4+3) = 0.5714. Finally, F1 is computed using precision and recall, scoring 2*((1*0.5714)/(1+0.5714))= 2*(0.5714/1.5714) = 0.7273.
NOTE: This is just an example. We are aware that achieving a precision score of 1.0 is quite a difficult task.
Sub-track 2: Sensitive span detection
For this second sub-track the goal is only to identify sensitive data. Thus, we will consider a span-based evaluation, regardless of the actual type of entity or the correct offset identification of multi-token sensitive phrase mentions.
Strict span evaluation
In the strict evaluation metric, the evaluation script will accept as correct annotations in the submissions that match exactly the start and end offset of the annotations in the GS file. For instance, it will accept as correct these tags:

But also the following ones, even if the entity tag and type are not specified (the system has submitted PHI and OTHER as ENTITY and TYPE, respectively):

Merged spans evaluation
For this sub-track we will also additionally compute another evaluation where we will merge the spans of PHI connected by non-alphanumerical characters. For instance, consider this tag in a GS file:

For the previous tag, in the merged spans evaluation, the script will accept as correct the following annotation (this example is also accepted by the strict span evaluation metric):

But also the following one, because the scripts merges the spans of the annotation if there are ony non-alphanumerical characters between them:

This merging process is carried out both in the GS file and in the system submission file. Therefore, the result is symmetric even if the larger span is given by the system (“Navarro Cuéllar” and “Ignacio” spans in the GS file and “Navarro Cuéllar, Ignacio” in the system file).