The evaluation will be done at CodaLab
Precision (P) = true positives/(true positives + false positives)
Recall (R) = true positives/(true positives + false negatives)
F-score (F1) = 2*((P*R)/(P+R))
Track A – Tweet binary classification
Submissions will be ranked by Precision, Recall and F1-score for the positive class (F-score is the primary metric).
Prediction format: tab-separated file with headers:
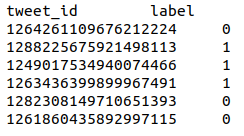
Track B – NER offset detection and classification
Submissions will be ranked by Precision, Recall and F1-score for each PROFESION [profession] or SITUACION_LABORAL [working status] mention extracted, where the spans overlap entirely (F-score is the primary metric).
A correct prediction must have the same beginning and ending offsets as the Gold Standard annotation, as well as the same label (PROFESION or SITUACION_LABORAL)
Prediction format: tab-separated file with headers. Same as the tab-separated format of the Gold Standard.

CodaLab
Predictions for each subtask should be contained in a single .tsv (tab-separated values) file. This file (and only this file) should be compressed into a .zip file. Please upload this zip file as submission. For the evaluation phase which will start on the 1st of March, you are allowed to add the validation set to the training set for training purposes.
Codalab: https://competitions.codalab.org/competitions/28766
- Register and wait for approval
- To make submissions : Participate -> Submit/View Results -> Click on Task -> Click Submit -> Select File
Refresh your submission. It goes from Submitted -> Running -> Finished. Scores should be available in the files. You can choose to submit your best scores to the Leaderboard. - To view results : Results -> Click on Task -> View results in table
You will be allowed to make unlimited submissions during the validation stage. During the evaluation stage only 2 submissions will be allowed.