- Lasige-BioTM: https://github.com/lasigeBioTM/LASIGE-participation-in-ProfNER
- Recognai: https://github.com/recognai/profner
- TroyAndAbendInTheMorning: https://github.com/ssantamaria94/ProfNER-SMM4H
- BSC Baseline: https://github.com/tonifuc3m/profner-baseline
Description of the Corpus
Training and validation (annotated), test and background (unannotated) datsets
The SMM4H-Spanish corpus is a collection of 10,000 health-related tweets in Spanish annotated with professions, employment statuses and other work-related activities. The aim of the corpus is to extract professions from social media to enable characterizing health-related issues, in particular in the context of COVID-19 epidemiology as well as mental health conditions.
The data of the corpus was obtained from a Twitter crawl that used keywords like “Covid-19”, “epidemia” (epidemic) or “confinamiento” (lockdown), as well as hashtags such as “#yomequedoencasa” (#istayathome), to retrieve relevant tweets. This crawl was further filtered to obtain only the tweets that were written both from Spain and in Spanish.
The corpus was annotated by linguist experts in an iterative process that included the creation of annotation guidelines specifically for this task. These guidelines are described and available for download here.
We have performed a consistency analysis of the corpus. 10% of the documents have been annotated by an internal annotator as well as by the linguist experts. The preliminary Inter-Annotator Agreement (pairwise agreement) is 0.919.
The annotation process was performed using the web-based tool brat. Below is an example of how the annotated tweets look like:

All in all, 10,000 tweets were annotated. They were split into 60% training (6,000), 20% development (2,000) and 20% test (2,000). The different splits can be downloaded here.
FORMAT
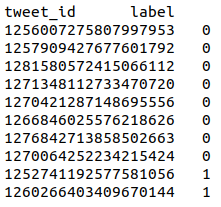
Track A – Tweet binary classification. Annotations are stored in a tab-separated file with 2 columns:
tweet_id label
Track B – Tweet binary classification. Annotations are stored in a tab-separated file with 5 columns:
tweet_id begin end type extraction

In addition, the corpus of Track B is provided in Brat format and in the IOB tagging scheme. See it on Zenodo.
Datasets
Training and validation (annotated), test and background (unannotated) datsets
Train set
The train set contains around 6,000 annotated tweets. Find it in Zenodo
Validation set
The validation set contains around 2,000 annotated tweets. Find it in Zenodo
Test and Background sets
The test set contains around 2,000 tweets. The background set contains 25K tweets. Find it in Zenodo.
You must submit predictions for the test and background sets. But you will only be evaluated for the test set predictions.
Test set with Gold Standard annotations
The Gold Standard annotations of the test set will be released after the submission deadline
Additional Resources
Evaluation Script
- Official evaluation script: TBD
Linguistic Resources
- CUTEXT. See it on GitHub.
Medical term extraction tool.
It can be used to extract relevant medical terms from tweets. - SPACCC POS Tagger. See it on GitHub.
Part Of Speech Tagger for Spanish medical domain corpus.
It can be used as a component of your system. - NegEx-MES. See it on Zenodo and on GitHub.
A system for negation detection in Spanish clinical texts based on NegEx algorithm.
It can be used as a component of your system. - AbreMES-X. See it on Zenodo.
Software used to generate the Spanish Medical Abbreviation DataBase. - AbreMES-DB. See it on Zenodo.
Spanish Medical Abbreviation DataBase.
It can be used to fine-tune your system. - MeSpEn Glossaries. See it on Zenodo.
Repository of bilingual medical glossaries made by professional translators.
It can be used to fine-tune your system. - Occupations gazetteer. See it on Zenodo.
A gazetter of occupations extracted from a set of terminologies (DeCS, ESCO, SnomedCT and WordNet) and Stanford CoreNLP.
Word embeddings
- FastText Spanish medical embeddings. See them on Zenodo.
Word and subword embeddings trained for medical Spanish domain.
It can be used as a component of your system. - FastText Spanish Twitter embeddings. See them on Zenodo.
Word and subword embeddings trained with Spanish Twitter data related to COVID-19.
It can be used as a component of your system.
Baseline
More resources TBD
Annotation Guidelines
Training and validation (annotated), test and background (unannotated) datasets
The SMM4H-Spanish corpus was manually annotated by linguist experts following the SMM4H-Spanish guidelines. These guidelines contain rules for annotating professions, employment statuses and work-related activities in health-related tweets in Spanish. Additionally, they also include some considerations regarding the codification of the annotations to the ESCO and SNOMED-CT taxonomies.
Guidelines were created de novo in three phases:
- First, a zero version of the guidelines was developed after annotating a initial batch of ~200 tweets and outlining the main problems and difficulties of the data.
- Second, a stable version of guidelines was reached while annotating sample sets of the ProfNER corpus iteratively until quality control was satisfactory.
- Third, guidelines are iteratively refined as manual annotation continues.
The annotation guidelines are available in Spanish here and in English here.