TBD
Evaluation Library
TBD
The evaluation will be done at CodaLab
Registration
To participate in a task, register (for free) on Google Form.
Please, choose a team name you remember since we will use it throughout the whole competition!
Student registrants are required to provide the name and email address of a faculty team member who has agreed to serve as their advisor/mentor for developing their system and writing their system description (see below). By registering for a task, participants agree to run their system on the test data and upload at least one set of predictions to CodaLab. Teams may upload up to three sets of predictions per task. By receiving access to the annotated tweets, participants agree to Twitter’s Terms of Service and may not redistribute any portion of the data.
Premios
TBD
Results
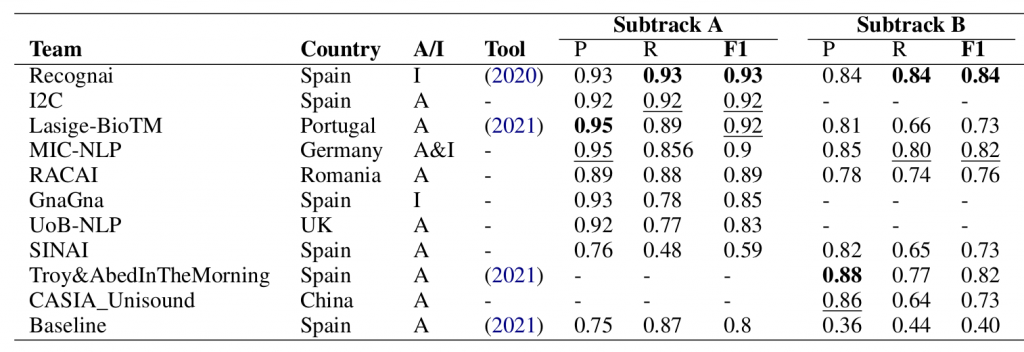
Please, cite the paper results: https://www.aclweb.org/anthology/2021.smm4h-1.3.pdf
Annotation Guidelines
Training and validation (annotated), test and background (unannotated) datasets
The SMM4H-Spanish corpus was manually annotated by linguist experts following the SMM4H-Spanish guidelines. These guidelines contain rules for annotating professions, employment statuses and work-related activities in health-related tweets in Spanish. Additionally, they also include some considerations regarding the codification of the annotations to the ESCO and SNOMED-CT taxonomies.
Guidelines were created de novo in three phases:
- First, a zero version of the guidelines was developed after annotating a initial batch of ~200 tweets and outlining the main problems and difficulties of the data.
- Second, a stable version of guidelines was reached while annotating sample sets of the ProfNER corpus iteratively until quality control was satisfactory.
- Third, guidelines are iteratively refined as manual annotation continues.
The annotation guidelines are available in Spanish here and in English here.