MESINESP2: Medical Semantic Indexing in Spanish Shared Task
This year the task was part of BioASQ Challenge. The 9th BioASQ Workshop was held as a Lab in CLEF 2021, on September 21-24, 2021, in Bucharest – Romania.
The BioASQ MESINESP Task is sponsored by the Secretaría de Estado para el Avance Digital (SEAD) and the Plan de Impulso de las Tecnologías del Lenguaje (Plan TL).
Generated Resources
- Overview Paper: http://ceur-ws.org/Vol-2936/paper-11.pdf
- Data: Gold Standard and Silver Standard
- Conference Proceedings: http://ceur-ws.org/Vol-2936/
- Evaluation Library: https://github.com/BioASQ/Evaluation-Measures
- Annotation Guidelines: http://metodologia.lilacs.bvsalud.org/download/E/LILACS-4-ManualIndexacao-es.pdf
- Youtube playlist: https://tinyurl.com/mesinesp2videos
Please, cite us using the following references:
- Luis Gasco, Anastasios Nentidis, Anastasia Krithara, Darryl Estrada-Zavala, Renato Toshiyuki Murasaki, Elena Primo-Peña, Cristina Bojo-Canales, Georgios Paliouras, Martin Krallinger. Overview of BioASQ 2021-MESINESP track. Evaluation of advance hierarchical classification techniques for scientific literature, patents and clinical trials. Proceedings of the Working Notes of CLEF 2021 – Conference and Labs of the Evaluation Forum , CEUR Workshop Proceedings. 165-187 (2021).
- A. Nentidis, G. Katsimpras, E. Vandorou, A. Krithara, L. Gasco, M. Krallinger, G. Paliouras. Overview of bioasq 2021: The ninth bioasq challenge on large-scale biomedical semantic indexing and question answering, 2021. arXiv:2106.14885
@inproceedings{gasco2021overview,
title={Overview of BioASQ 2021-MESINESP track. Evaluation of advance hierarchical classification techniques for scientific literature, patents and clinical trials},
author={Gasco, Luis and Nentidis, Anastasios and Krithara, Anastasia and Estrada-Zavala, Darryl and Murasaki, Renato Toshiyuki and Primo-Pe{\~n}a, Elena and Bojo Canales, Cristina and Paliouras, Georgios and Krallinger, Martin and others},
year={2021},
organization={CEUR Workshop Proceedings}
}
@inproceedings{nentidis2021overview,
title={Overview of BioASQ 2021: The Ninth BioASQ Challenge on Large-Scale Biomedical Semantic Indexing and Question Answering},
author={Nentidis, Anastasios and Katsimpras, Georgios and Vandorou, Eirini and Krithara, Anastasia and Gasco, Luis and Krallinger, Martin and Paliouras, Georgios},
booktitle={International Conference of the Cross-Language Evaluation Forum for European Languages},
pages={239--263},
year={2021},
organization={Springer}
}
Schedule
| Date | Event |
|---|---|
| March 17 | "Sub-track 1" training and development set release |
| March 17 | "Sub-track 2" training and development set release |
| April 19 | "Sub-track 1" test set release |
| April 19 | "Sub-track 2" test set release |
| April 19 | "Sub-track 3" development and test set release |
| April 19 | Additional datasets release (Medical entities present in documents) |
| MAy, 7 to May, 13 | Evaluation period of "Sub-track 1". Guidelines |
| April , 30 | BioASQ9 Lab @CLEF 2021 Registration Deadline |
| May, 13 to May, 17 | Evaluation period of "Sub-track 2". Guidelines |
| May, 17 to May, 19 | Evaluation period of "Sub-track 3". Guidelines |
| May 28, 2021 | Submission of Participant Papers at CLEF2021 |
| June 11, 2021 | Notification of acceptance (peer-reviews). |
| July 2, 2021 | Camera ready paper submission. |
| September 21-24, 2021 | The 9th BioASQ Workshop @CLEF 2021 (Bucharest, Romania) |
Motivation
There is a pressing need to improve the access to information comprised in health and biomedicine related documents, not only by professional medical users buy also by researches, public healthcare decision-makers, and other healthcare professionals.
Semantic indexing with medical vocabularies has resulted in a good solution to reduce costs and the time bottlenecks in document indexing. The importance of these technologies motivated several-shared tasks in the past, in particular the BIOASQ tracks, with a considerable number of participants and impact in the field for medical literature in English.
Most of the Biomedical NLP and IR research is being done on English documents, but it is important to note that there is a considerable amount of medically relevant content published in other languages than English. Something especially relevant in clinical texts and patents, which are entirely written in the native language of each country, with a few exceptions.
The MESINESP2 shared-task invites researchers, medical, and industry professionals to develop automatic semantic indexing systems with structured medical vocabularies for Spanish documents, which is one of the most widely spoken languages in the world with over 572 million speakers.. The overview of this year’s task is shown in the figure:
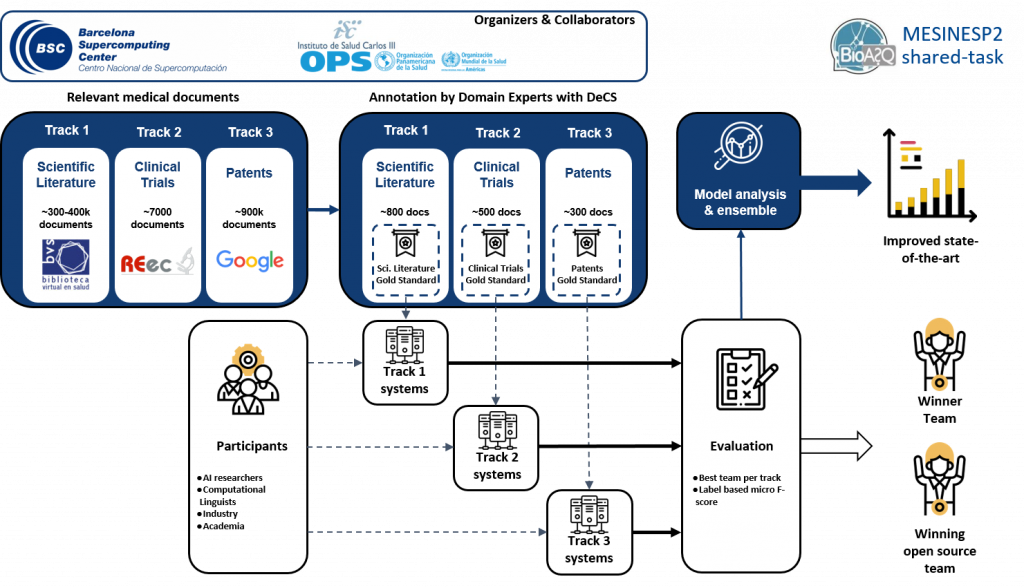
This year, we propose once again the semantic indexing of Spanish scientific medical literature, but as a novelty, we include two new sub-tracks, each one proposing the semantic indexing of other types of medical documents:
- MESINESP-L – Scientific Literature [Subtrack 1]: This track will require automatic indexing with DeCS terms of abstracts using two highly used databases in Spanish (IBECS and LILACS).
- MESINESP-T- Clinical Trials [Subtrack 2]: This track will require automatic indexing with DeCS terms of clinical trials from REEC (Registro Español de Estudios Clínicos).
- MESINESP-P – Patents [Subtrack 3]: This track will require automatic indexing with DeCS terms the content of Spanish patents extracted from Google Patents.
For this task, we have prepared a set of corpora that can be examined deeply in the data section.
Semantic indexing of content is a demanding and complex task. Therefore, in addition to the datasets of documents with DeCS descriptors, and given the extensive experience of the Barcelona Supercomputing Center in biomedical NERs in Spanish, we have extracted entities related to drugs, diseases, symptoms and medical procedures for each record of the corpora.

If you want to consult a more-detailed explanation of the task, you can read it in the task section.