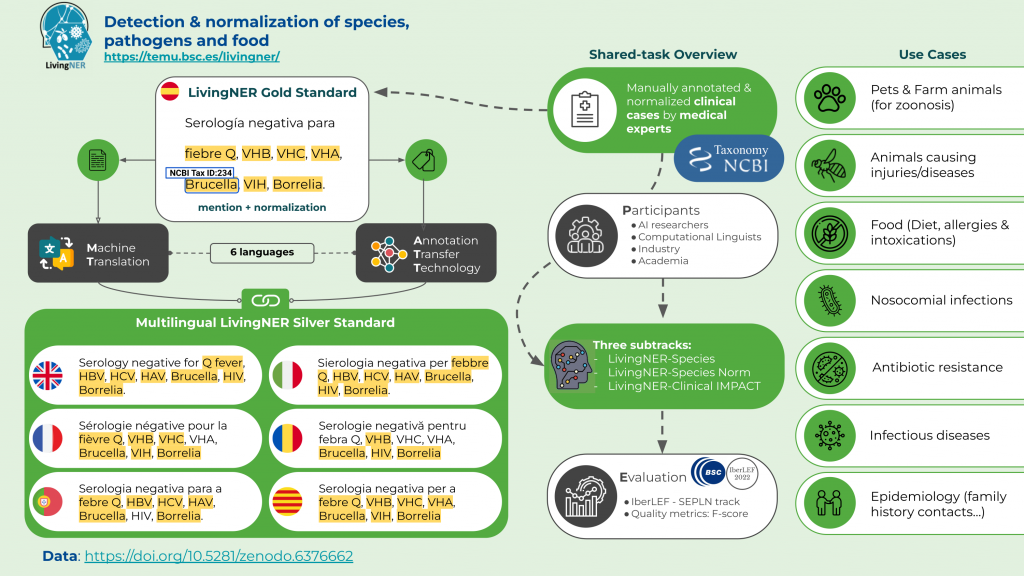
Multilingual corpus
Download the LivingNER corpus (including the multilingual corpus) from zenodo
We have generated the annotated (and normalized to NCBI Taxonomy) training and validation sets in 6 languages: English, Portuguese, Catalan, Italian, French, and Romanian. The process was:
- The text files were translated with a neural machine translation system.
- The annotations were translated with the same neural machine translation system.
- The translated annotations were transferred to the translated text files using an annotation transfer technology.
If you want to visualize the multilingual resources, check out this Brat server: https://temu.bsc.es/mLivingNER/#/translations/
For instance, you can see the parallel annotations in English vs in French, or in Spanish (the gold standard) vs in Italian.
LivingNER Annotation Guidelines
Download the annotation guidelines from Zenodo.
The LivingNER corpus was manually annotated by clinical experts following annotation guidelines specifically created for this task. These guidelines contain rules for annotating species and infectious diseases in clinical cases in Spanish. Infectious diseases are not included in this task. Additionally, they also include some considerations regarding the codification of the annotations to the NCBI Taxonomy.
Guidelines were created de novo in three phases:
- First, a zero version of the guidelines was developed after annotating an initial batch of ~40 clinical cases and outlining the main problems and difficulties of the data.
- Second, a stable version of guidelines was reached while annotating sample sets of the LivingNER corpus iteratively until quality control was satisfactory.
- Third, guidelines are iteratively refined as manual annotation continues.
The annotation guidelines are available in Zenodo.

LivingNER corpus post-annotation review steps:
- Consistency review: all annotations were searched for occurrences in all documents and a clinical expert reviewed whether they should be added to the annotations.
- False positives: all annotations for the entities “neonatología”, “personalidad”, “cocaína”, “sociofamiliares”, “politraumatizado” were eliminated.
- False negatives: the occurrences in the text of “prion”, “contacto sexual”, “oportunistas”, “enfermedades oportunistas”, “fascitis necrosante”, “fascitis necrotizante”, “probióticos” were reviewed and revised if they should be annotated because they are very important.
- Consistency in the annotation of labels: there are mentions that sometimes are SPECIES and sometimes ENFERMEDAD and they were reviewed.
- Validation of standardization: all codes were checked to ensure that they were in the official version of NCBI Taxonomy.
- Consistency of standardization: there are some mentions that have different codes depending on the context. These were reviewed.
- Review of unmapped entities: we reviewed all mentions without codes.
- Checking internal line breaks: annotations with line break characters inside them were removed as they span more than one line.
- Annotation starting and ending characters: all annotations are checked to ensure that they start and end with an alphanumeric character or a parenthesis. For example (“,adenocarcinoma,” would be an erroneous annotation since it is surrounded by commas).
Datasets
Download the training, validation, test and background sets from Zenodo.
The LivingNER corpus has been randomly sampled into three subsets: train, development and test set.
Sample set
The sample set is composed of 5 clinical cases extracted from the training set from four different specialties: COVID, oncology, infectious diseases and tropical medicine.
Download the sample set from Zenodo.
Training set
The training set is composed of 1000 clinical cases from many different specialties: COVID, oncology, infectious diseases, tropical medicine, etc.
Download the training set from Zenodo.
Development set
The training set is composed of 500 clinical cases from many different specialties: COVID, oncology, infectious diseases, tropical medicine, urology, allergology, etc.
Download the validation set from Zenodo.
Test set
The test set is composed of clinical cases from many different specialties. It is released WITHOUT ANNOTATIONS. The goal of the task is to generate automatic annotations for the test set documents.
The test set is released together with a large collection of clinical case reports (background set), to avoid manual annotations.
Download the test+background set from Zenodo.
LivingNER corpus description
Download the corpus from zenodo
This page contains the following information:
1. General information
The LivingNER Gold Standard consists of a collection of 2000 clinical case reports that will be distributed in plain text in UTF8 encoding, where each clinical case would be stored as a single file. Additionally, we will also provide the annotation files comprising the character offsets of the entity mentions in TSV (tab-separated values) files together with their corresponding NCBI Taxonomy code annotations.

The clinical case reports come from 20 medical disciplines (enfermedades infecciosas (incluidos casos de Covid-19), cardiología, neurología, oncología, otorrinolaringología, odontología, pediatría, endocrinología, atención primaria, alergología, radiología, psiquiatría, oftalmología, psiquiatría, urología, medicina interna, emergencias y medicina de cuidados intensivos, radiología, medicina tropical y dermatología) with species [SPECIES] and [HUMAN] entities manually annotated.
The corpus’ content is quite varied, as it includes annotations for animals, plants, and microorganisms (including bacteria, fungi, viruses, and parasites). Both scientific names, as well as common names, were considered.
All of these mentions have been manually mapped to the NCBI taxonomy. Please, beware that:
- Composite mentions. If several NCBI taxonomy codes were required to map a single annotated mention, the codes are concatenated with a “|” symbol. For instance, “microorganism” is mapped to “2|2759|10239”.
- Terminology codes that are more general than the annotated mention. If the NCBI taxonomy concept was more general than the annotated mention, the modifier “H” is added to the NCBI taxonomy code. For instance, “baciloscopia” is mapped to “2|H”.
The final corpus will be randomly split into three subsets: training, development and test. In the case of training and development sets, additionally, to the clinical cases, a TSV file will be released. It will contain one row per annotation.
In addition to the test set, a larger background set of clinical case documents will be released to make sure that participating teams will not be able to do manual corrections.
The goal of the LivingNER task is to develop automatic systems for Spanish medical texts. These systems should rely on the use of the LivingNER corpus, a high-quality Gold Standard synthetic clinical corpus of 2000 records based on a manual annotation process done by human experts together with an inter-annotator agreement consistency analysis.
2. Corpus format
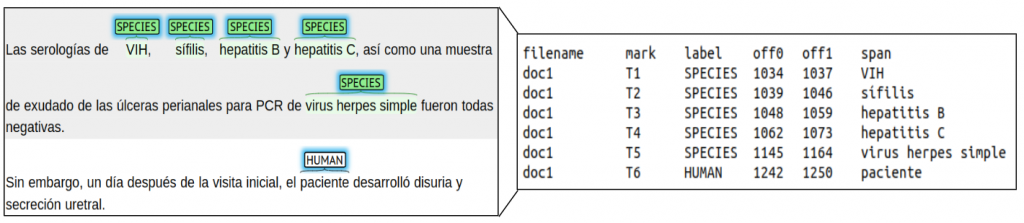
For subtask 1 (LivingNER – Species NER), annotations are distributed in a tab-separated file (TSV) file with the following columns:
- filename: document name
- mark: identifier mention mark
- label: mention type (SPECIES or HUMAN)
- off0: starting position of the mention in the document
- off1: ending position of the mention in the document
- span: textual span
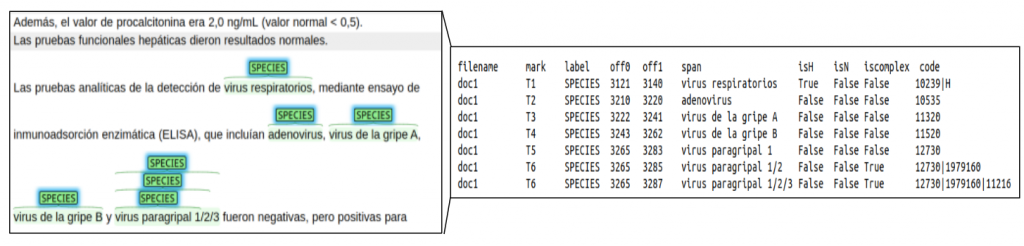
For subtask 2 (LivingNER – Species Norm), annotations are distributed in a TSV file with the same columns as the previous one, plus:
- isH: whether the span is narrower than the NCBITax assigned code
- isN: whether the mention corresponds to a nosocomial infection
- iscomplex: whether the span has assigned a combination of NCBITax codes
- NCBITax: mention code in the NCBI Taxonomy
For subtask 3 (LivingNER – Clinical IMPACT), annotations are distributed in a (TSV) with the following columns:
- filename
- isPet (Yes/No)
- PetIDs (NCBITaxonomy codes of pet & farm animals present in document)
- isAnimalInjury (Yes/No)
- AnimalInjuryIDs (NCBITaxonomy codes of animals causing injuries present in document)
- IsFood (Yes/No)
- FoodIDs (NCBITaxonomy codes of food mentions present in document)
- isNosocomial (Yes/No)
- NosocomialIDs (NCBITaxonomy codes of nosocomial species mentions present in document)

All text files are distributed as plain UTF-8 text files, where each clinical case would be stored as a single file.
Resources
LivingNER Resources
LivingNER terminology – codes Reference List
- Reference list with all valid codes from NCBI Taxonomy with the terms translated to Spanish. It is a .tsv file. Available in Zenodo
LivingNER evaluation script
Other Resources
Word embeddings
- Spanish Medical Word Embeddings. Word embeddings generated from Spanish medical corpora. Download them from Zenodo.
It can be used as a building block for clinical NLP systems used in Spanish texts.
Linguistic Resources
- CUTEXT. See it on GitHub.
Medical term extraction tool.
It can be used to extract relevant medical terms from clinical cases. - SPACCC POS Tagger. See it on Zenodo.
Part Of Speech Tagger for Spanish medical domain corpus.
It can be used as a component of your system. - NegEx-MES. See it on Zenodo.
A system for negation detection in Spanish clinical texts based on NegEx algorithm.
It can be used as a component of your system. - Negation corpus. See it on GitHub
A Corpus of Negation and Uncertainty in Spanish Clinical Texts (and instructions to train the system). - AbreMES-X. See it on Zenodo.
Software used to generate the Spanish Medical Abbreviation DataBase. - AbreMES-DB. See it on Zenodo.
Spanish Medical Abbreviation DataBase.
It can be used to fine-tune your system. - MeSpEn Glossaries. See it on Zenodo.
Repository of bilingual medical glossaries made by professional translators.
It can be used to fine-tune your system.