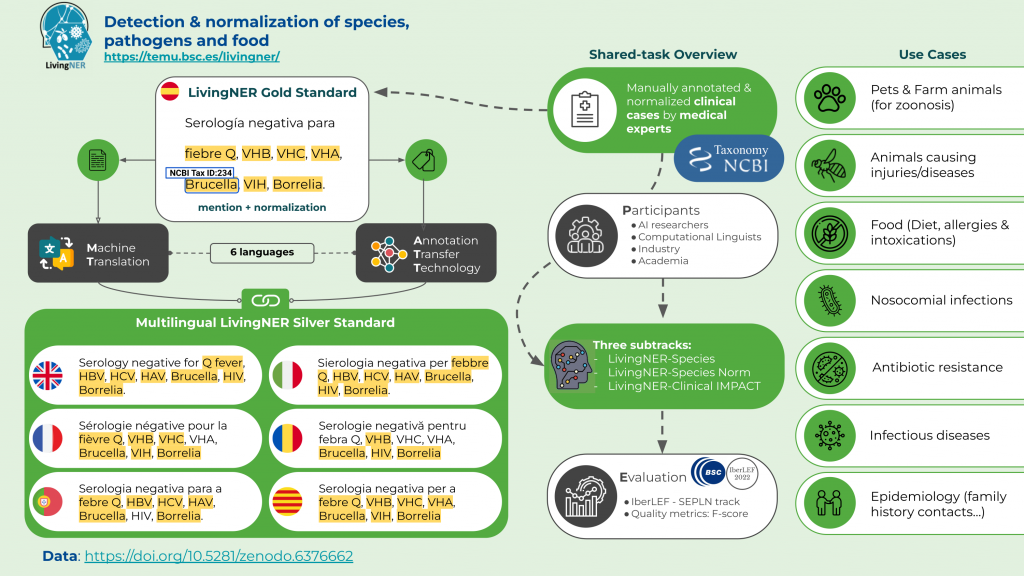
Download the LivingNER corpus (including the multilingual corpus) from zenodo
We have generated the annotated (and normalized to NCBI Taxonomy) training and validation sets in 6 languages: English, Portuguese, Catalan, Italian, French, and Romanian. The process was:
- The text files were translated with a neural machine translation system.
- The annotations were translated with the same neural machine translation system.
- The translated annotations were transferred to the translated text files using an annotation transfer technology.
If you want to visualize the multilingual resources, check out this Brat server: https://temu.bsc.es/mLivingNER/#/translations/
For instance, you can see the parallel annotations in English vs in French, or in Spanish (the gold standard) vs in Italian.