
The proposed task will use a subset of 1.5 million words from three main sources:
- Legislative text from the Official Bulletin of the State (Boletín Oficial de Estado-BOE)
- Open Public Sentences
- Public Procurement.
All sources were developed within Plan TL from open public data. The three subsets consist of a collection randomly extracted fragments, each of approximately 500 tokens.
A sample of the three sources is available here:
- Official Bulletin of the State (Boletin Oficial de Estado-BOE) sample

- Sentence Sample

- Recruitment sample
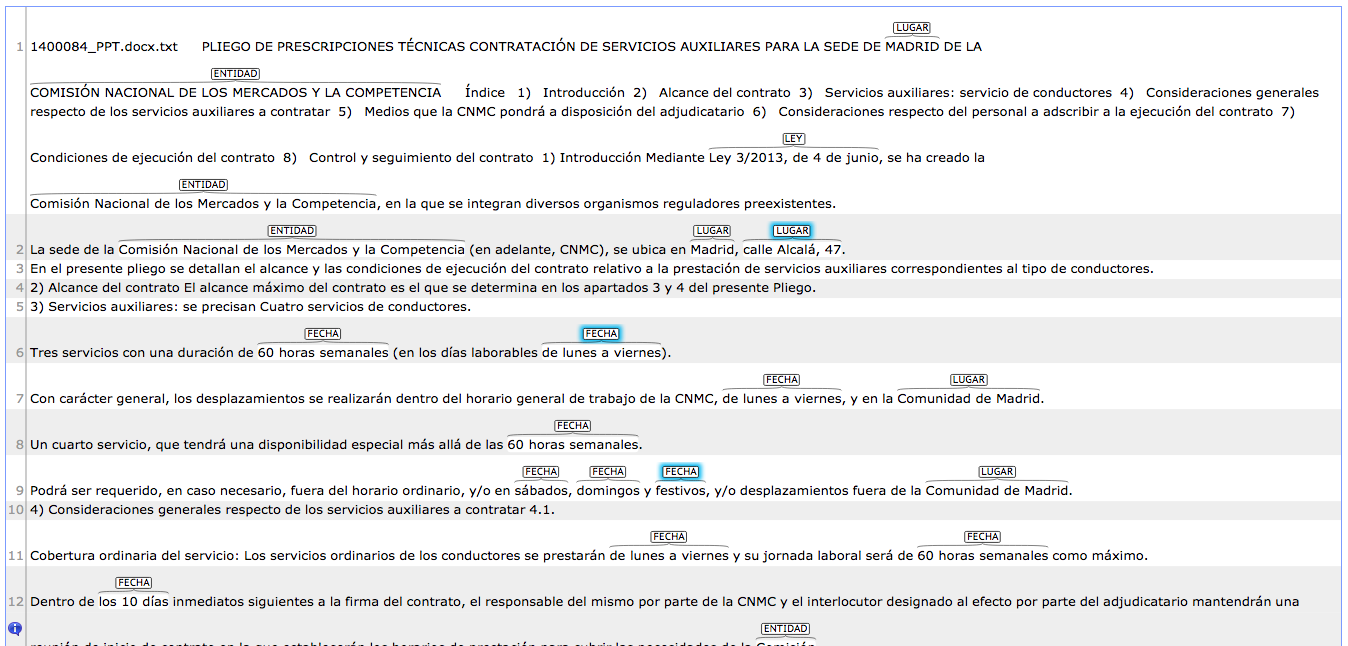
The following is an example:

It is important to point out that some Named in Legal texts has special characteristics. For example, mentions of laws might include time expressions with references to dates (months or years). These aspects are taken into consideration, nevertheless the organizing team decided to opt for the annotation at one level as a Mention of Law and not to include sub-categories within the Named Entity.
Each subset consists of approximately 500, 000 words distributed in plain-text fragments of an average length of 500-2000 words each. The following table represents teh distribution of the fragments among the three subsets:
| Subset | Number of fragments | Average length of each fragment (tokens) |
| BOE | 933 | 500 |
| Public Procurement | 204 | 2450 |
| Sentences | 400 | 1250 |