In this section, we show examples of how the evaluation will be carried out to make it clearer.
Sub-track 1: NER offset
In this
Gold Standard example
For the following examples, we will consider that this set of PharmaCoNER tags is our Gold Standard (GS):
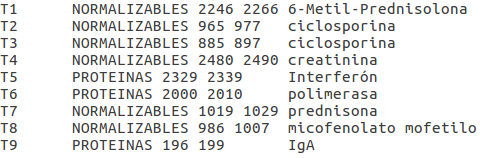
This GS file is in brat format. We have six
NOTE: The ID and TEXT fields are not used for any of the evaluation metrics. The number in the ID field is arbitrary, and the evaluation of the TEXT field is implicit in the offset evaluation, as the text is the same for the GS and the systems.
System submission example
The following system annotations will be accepted by the evaluation script even if the IDs numbers do not match.
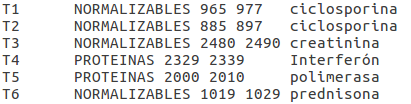
For this example the scores obtained by this system are the following:
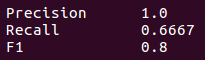
Precisión has been computed dividing true positives (6) by the sum of true positives and false positives (0), scoring 6/(6+0) = 1.0.
NOTE: This is just an example. We are aware that achieving a precision score of 1.0 is quite a difficult task.
Sub-track 2: Concept Indexing
The second evaluation scenario will consist of a concept indexing task where for each document, the list of unique SNOMED concept identifiers have to be generated by participating teams, which will be compared to the manually annotated concept ids corresponding to chemical compounds and pharmacological substances.
Gold Standard example
For the following examples, we will consider that this set of PharmaCoNER tags is our Gold Standard (GS):

This GS file is in
System submission example
For

For this example the scores obtained by this system are the following:
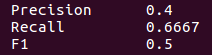
Precisión has been computed dividing true positives (2) by the sum of true positives and false positives (0), scoring 2/(2+3) = 0.4.