The annotation process of the
This iterative refinement process required direct interaction between the expert annotators in order to resolve discrepancies, using a side-by-side visualization of clinical case document annotations with the high lightened discrepancies and going over each of them in order to solve doubts, add rules and add clarifying examples to the guidelines. A common aspect that needed to be clarified was the annotation in the first sample annotation cycle of therapeutic application types that actually did not correspond to a chemical entity per se. The final, inter-annotator agreement measure obtained for this corpus was calculated on a set of 50 records that were double annotated (blinded) by two different expert annotators, reaching a pairwise agreement of 93% on the exact entity mention comparison level and 76% agreement when also the entity concept normalization was taken into account. Entity normalization was carried out primarily against the SNOMED-CT knowledgebase. Note that there is SNOMED CT version directly released by the Spanish Ministry of Health.
The manual annotation of the entire corpus was carried out in a three-step approach. First, an initial annotation process was carried out on an adapted version of the AnnotateIt tool. The resulting annotations were then exported, trailing whitespaces were removed and double annotations of the same string were send as an alert to the human annotators for revision/correction. Then, the annotations were uploaded into the BRAT annotation tool, which was slightly less efficient for mention labeling in terms of manual annotation speed. The human annotators performed then a final revision of the annotation in BRAT, to correct mistakes and to add missing annotation mentions. Finally, the senior annotator did
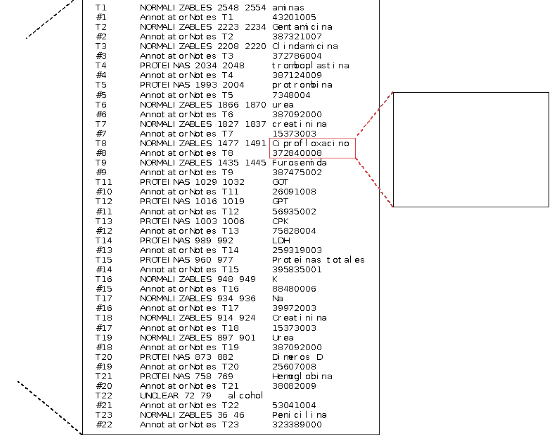
The annotation of the entire set of entity mentions was carried out by medicinal chemistry experts, who in case of doubts regarding more clinically related concept mentions consulted the directly the practicing physicians collaborating with this annotation project. Moreover, technical assistance in terms of the annotation interface was offered during the entire corpus development process. Figure 3 shows the previous example case together with its corresponding textual annotation in the BRAT format and the clarification of the normalization of one specific entity mention.