General information
The MEDDOPROF corpus is a collection of 1844 clinical cases from over 20 different specialties annotated with professions and employment statuses. The corpus was annotated by a team composed of linguists and clinical experts following specially prepared annotation guidelines, after several cycles of quality control and annotation consistency analysis before annotating the entire dataset. Figure 1 shows a screenshot of a sample manual annotation generated using the brat annotation tool.

The corpus will be distributed in plain text in UTF8 encoding, where each clinical case would be stored as a single file. These clinical case reports were carefully selected to represent records reflecting as much as possible clinical narrative related to electronic clinical reports, including cases from around 20 different medical specialties (such as infectious diseases (including Covid-19 case reports), cardiology, neurology, oncology, psychiatry, urology, internal medicine, emergency and intensive care medicine, radiology, tropical medicine, …). Figure 2 illustrates an example text snippet corresponding to a short sample record.

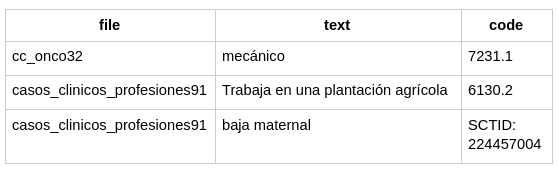
Additionally, we will also provide the annotation files comprising the character offsets of the tumor morphology entity mentions in TSV (tab-separated values) BRAT format and a TSV file with each individual mapped to the European Skills, Competences, Qualifications and Occupations (ESCO) classification and SNOMED-CT.
The goal of the MEDDOPROF task is to develop automatic occupation detection systems for Spanish medical texts. These systems should rely on the use of the MEDDOPROF corpus, a high-quality Gold Standard clinical corpus of 3000 records based on a manual annotation process done by human clinical coding experts together with an inter-annotator agreement consistency analysis.
The MEDDOPROF task can be approached as a named entity recognition and normalization task. Participants are encouraged to either propose solutions in one of these directions or to combine both approaches. As well, novel approaches are welcomed.
Corpus format
Track 1 – MEDDOPROF-NER: brat annotation format.

Track 2 – MEDDOPROF-CLASS: brat annotation format.

Track 3 – MEDDOPROF-NORM: we provide a single plain text file per clinical case and a tab-separated file with each mention’s code. SNOMED-CT codes have the prefix ‘SCTID:’.