As a complement to the Gold Standard MEDDOPROF corpus, we have updated the training data to include additional mentions of automatically labelled annotations that may be used (or not) by participants in their system. This complement is called MEDDOPROF-CE (Complementary Entities).
The CE version of the training data includes the Shared Task’s original manual annotations (with the labels for task one and two joint together, e.g. “PACIENTE-PROFESION”) and automatically generated clinical and linguistic entities. All in all, nine new entity types have been included: “síntoma” (symptom), “enfermedad” (disease), “procedimiento” (procedure), “fármaco” (drug), “org_vivo” (living organisms), “neg”/”nsco” (negation trigger and scope) and “unc”/”usco” (uncertainty trigger and scope).
The entities in the MEDDOPROF-CE version will not be evaluated in the task, but they can be used to test the impact of other entity types in the Shared Task’s tracks or for information discovery. We encourage participants to be creative and incorporate these additional layers into their systems as they wish.
The Complementary Entities dataset can be downloaded together with the training data on Zenodo.
CUTEXT.See it on GitHub. Medical term extraction tool. It can be used to extract relevant medical terms from tweets.
SPACCC POS Tagger.See it on GitHub. Part Of Speech Tagger for Spanish medical domain corpus. It can be used as a component of your system.
NegEx-MES. See it on Zenodo and on GitHub. A system for negation detection in Spanish clinical texts based on NegEx algorithm. It can be used as a component of your system.
AbreMES-X.See it on Zenodo. Software used to generate the Spanish Medical Abbreviation DataBase.
AbreMES-DB.See it on Zenodo. Spanish Medical Abbreviation DataBase. It can be used to fine-tune your system.
MeSpEn Glossaries. See it on Zenodo. Repository of bilingual medical glossaries made by professional translators. It can be used to fine-tune your system.
Occupations gazetteer. See it on Zenodo. A gazetter of occupations extracted from a set of terminologies (DeCS, ESCO, SnomedCT and WordNet) and Stanford CoreNLP.
Word embeddings
FastText Spanish medical embeddings. See them on Zenodo. Word and subword embeddings trained for medical Spanish domain. It can be used as a component of your system.
The MEDDOPROF corpus was manually annotated by linguist experts following annotation guidelines specifically create for this task. These guidelines contain rules for annotating professions, employment statuses and work-related activities (which were not included in this task) in clinical cases in Spanish. Additionally, they also include some considerations regarding the codification of the annotations to the ESCO and SNOMED-CT taxonomies.
Guidelines were created de novo in three phases:
First, a zero version of the guidelines was developed after annotating a initial batch of ~200 clinical cases and outlining the main problems and difficulties of the data.
Second, a stable version of guidelines was reached while annotating sample sets of the MEDDOPROF corpus iteratively until quality control was satisfactory.
Third, guidelines are iteratively refined as manual annotation continues.
The annotation guidelines are available in Zenodo.
The sample set is composed of 15 clinical cases extracted from the training set. In order to make the sample set somewhat representative of the corpus, we included cases from four different specialties: radiology, oncology, psychiatry and occupational health.
For task 3 (MEDDOPROF-NORM), a reference list with all valid codes is provided. It is a .tsv file with three columns: code, label and alternative label. Codes from two sources are listed: ESCO and SNOMED-CT (these are preceded by the string ‘SCTID:’ in the list). With a few exceptions, professions are mapped to ESCO, while working statuses and activities are mapped to SNOMED-CT.
The MEDDOPROF corpus is a collection of 1844 clinical cases from over 20 different specialties annotated with professions and employment statuses. The corpus was annotated by a team composed of linguists and clinical experts following specially prepared annotation guidelines, after several cycles of quality control and annotation consistency analysis before annotating the entire dataset. Figure 1 shows a screenshot of a sample manual annotation generated using the brat annotation tool.
Figure 1. Example BRAT annotation with profession and employment status labels.
The corpus will be distributed in plain text in UTF8 encoding, where each clinical case would be stored as a single file. These clinical case reports were carefully selected to represent records reflecting as much as possible clinical narrative related to electronic clinical reports, including cases from around 20 different medical specialties (such as infectious diseases (including Covid-19 case reports), cardiology, neurology, oncology, psychiatry, urology, internal medicine, emergency and intensive care medicine, radiology, tropical medicine, …). Figure 2 illustrates an example text snippet corresponding to a short sample record.
Figure 2. Example plain text MEDDOPROF corpus document.
Additionally, we will also provide the annotation files comprising the character offsets of the tumor morphology entity mentions in TSV (tab-separated values) BRAT format and a TSV file with each individual mapped to the European Skills, Competences, Qualifications and Occupations (ESCO) classification and SNOMED-CT.
The goal of the MEDDOPROF task is to develop automatic occupation detection systems for Spanish medical texts. These systems should rely on the use of the MEDDOPROF corpus, a high-quality Gold Standard clinical corpus of 3000 records based on a manual annotation process done by human clinical coding experts together with an inter-annotator agreement consistency analysis.
The MEDDOPROF task can be approached as a named entity recognition and normalization task. Participants are encouraged to either propose solutions in one of these directions or to combine both approaches. As well, novel approaches are welcomed.
Figure 4. Example brat annotation for MEDDOPROF-CLASS.
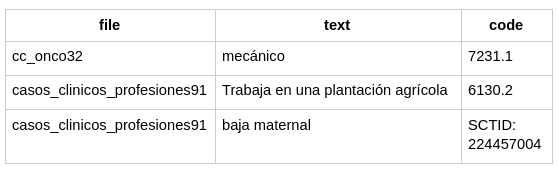
Track 3 – MEDDOPROF-NORM: we provide a single plain text file per clinical case and a tab-separated file with each mention’s code. SNOMED-CT codes have the prefix ‘SCTID:’.
Figure 5. Example tab-separated file for MEDDOPROF-NORM.